 k8s面试题
k8s面试题
# 1、k8s有哪些组件构成?
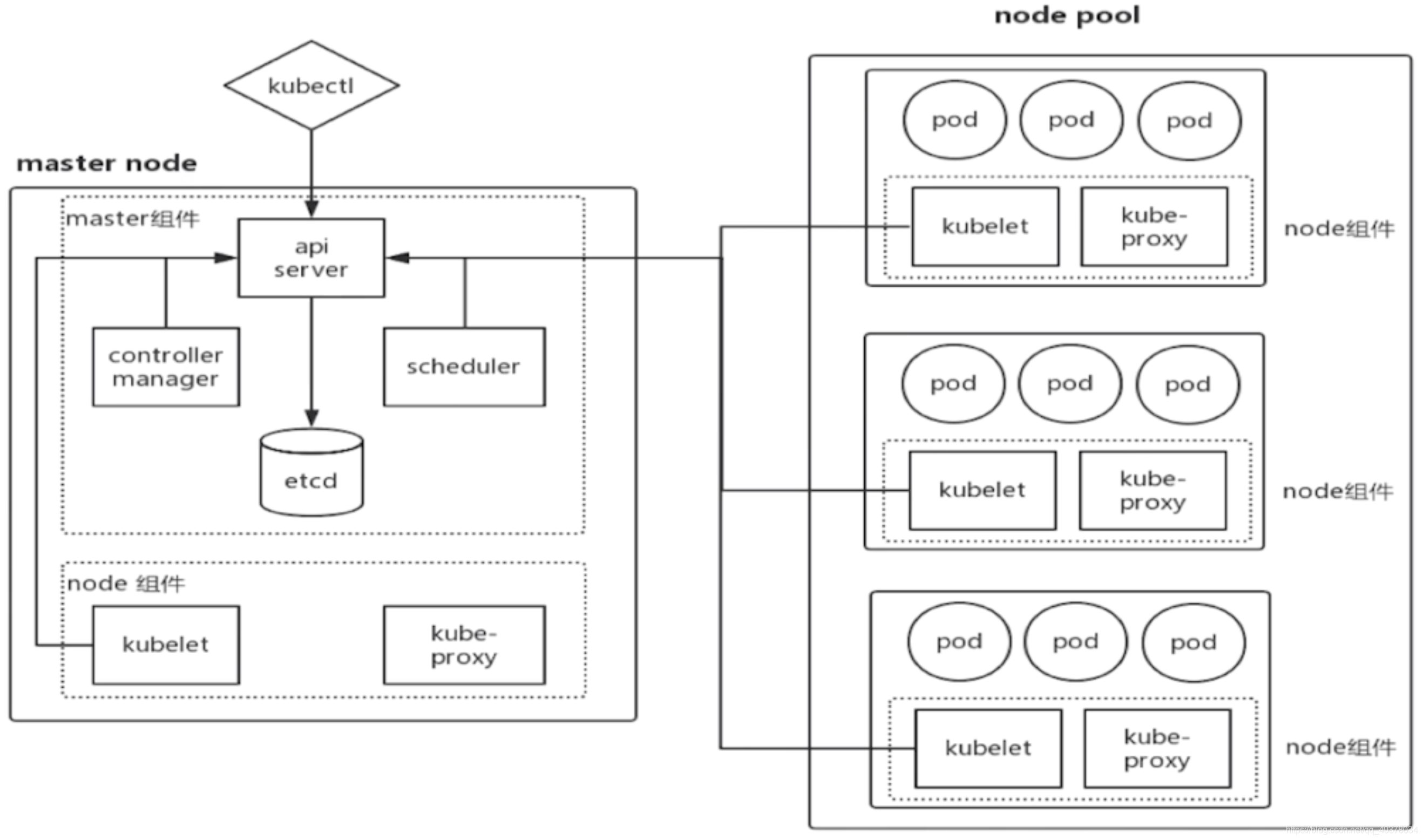
master和node是最主要的两个组件,这两个组件下又分为很多个小组件:
# 1)、Master
K8S中的Master是集群控制节点,负责整个集群的管理和控制
在Master上运行着以下关键进程:
**Kubernetes API Server:**提供了HTTP Rest接口的关键服务进程,其封装了核心对象的增删改查操作,以 RESTful API 接口方式提供给外部客户和内部组件调用,集群内各个功能模块之间数据交互和通信的中心枢纽。
**Kubernetes-controller-manager:**K8S里所有资源对象的自动化控制中心,集群内各种资源Controller的核心管理者,针对每一种资源都有相应的Controller,保证其下管理的每个Controller所对应的资源始终处于期望状态
**Kubernetes-scheduler:**负责资源调度(Pod调度,为新的Pod分配机器)的进程,通过API Server的Watch接口监听新建Pod副本信息,并通过调度算法为该Pod选择一个最合适的Node
Node Controller:管理维护 Node,定期检查 Node 的健康状态,标识出(失效|未失效)的 Node 节点。
(除此之外还有很多个Controller,负责不同的资源管理和调度)
**etcd:**K8S里的所有资源对象以及状态的数据都被保存在etcd中
# 2)、Node
Node是K8S集群中的工作负载节点,每个Node都会被Master分配一些工作负载,当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上
在每个Node上都运行着以下关键进程:
kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master密切协作,实现集群管理的基本功能
kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件
Docker Engine:Docker引擎,负责本机的容器创建和管理工作 在默认情况下Kubelet会向Master注册自己,一旦Node被纳入集群管理范围,kubelet进程就会定时向Master汇报自身的信息(例如机器的CPU和内存情况以及有哪些Pod在运行等),这样Master就可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node在超过指定时间不上报信息时,会被Master判定为失败,Node的状态被标记为不可用,随后Master会触发工作负载转移的自动流程
# 2、简述 Kubernetes 和 Docker 的关系
Docker是一个容器化平台,它以容器的形式将您的应用程序及其所有依赖项打包在一起,以确保应用程序在任何环境中无缝运行。
它的主要优点是将将软件/应用程序运行所需的设置和依赖项打包到一个容器中,从而实现了可移植性等优点。(容器化)
Kubernetes 用于关联和编排在多个主机上运行的容器,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。(为了让容器更高效)
# 3、 Kubernetes 中 Minikube、Kubectl、Kubelet 分别是什么?
Minikube 是一种可以在本地轻松运行一个单节点 Kubernetes 群集的工具。
Kubectl 是一个命令行工具,可以使用该工具控制 Kubernetes 集群管理器,如检查群集资源,创建、删除和更新组件,查看应用程序。
Kubelet 是一个代理服务,它在每个节点上运行,并使从服务器与主服务器通信。负责管理pod、images镜像、volumes、etc。
# 4、Kubernetes 外部如何访问集群内的服务?
对于 Kubernetes,集群外的客户端默认情况,无法通过 Pod 的 IP 地址或者 Service 的虚拟 IP 地址+虚拟端口号 进行访问。
通常可以通过以下方式进行访问 Kubernetes 集群内的服务:
1、映射 Pod 到物理机:将 Pod 端口号映射到宿主机,即在 Pod 中采用 hostPort 方式,以使客户端应用能够通过物理机访问容器应用。 2、映射 Service 到物理机:将 Service 端口号映射到宿主机,即在 Service 中采用 nodePort 方式,以使客户端应用能够通过物理机访问容器应用。 3、映射 Sercie 到 LoadBalancer:通过设置 LoadBalancer 映射到云服务商提供的 LoadBalancer 地址。这种用法仅用于在公有云服务提供商的云平台上设置 Service 的场景。
# 5、Kubernetes 创建一个 Pod 的主要流程
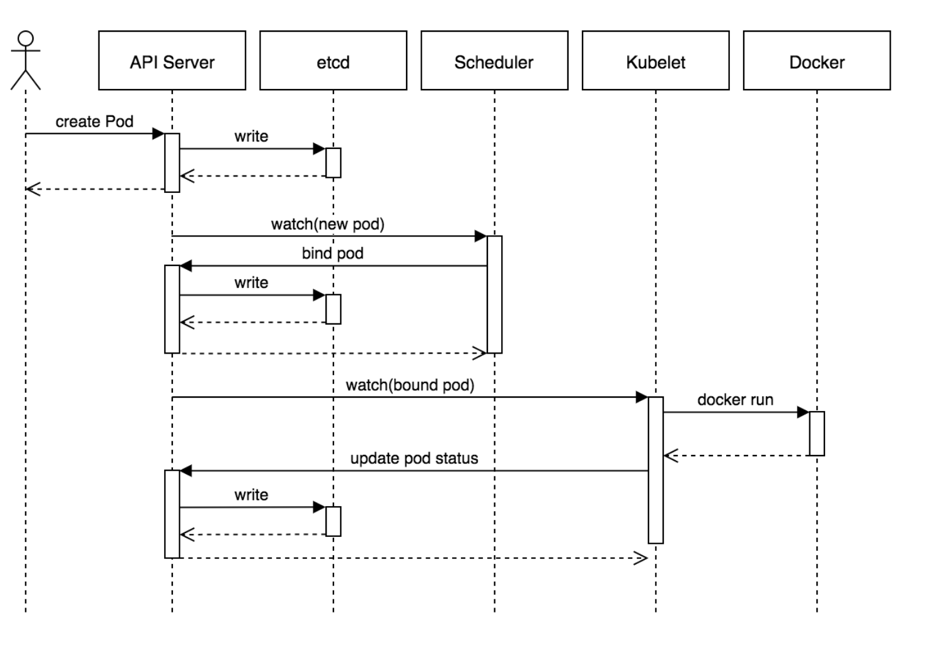
1、客户端提交 Pod 的配置信息(可以是Kubectl 命令行的 yaml / json 文件定义的信息,也可以是API Server的REST API)到 kube-apiserver
2、 kube-apiserver收到指令后,通知给 controller-manager 创建一个资源对象。然后Controller-manager 通过 api-server 将 pod 的配置信息存储到 ETCD 数据中心中。
3、Kube-scheduler 检测到 pod 信息会开始调度预选,会先过滤掉不符合 Pod 资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行 pod 的节点,然后将 pod 的资源配置单发送到 node 节点上的 kubelet 组件上。
这部分又细分为:
过滤主机:调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机;
主机打分:Kube-scheduler 检测到 pod 信息会开始调度预选,会先过滤掉不符合 Pod 资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行 pod 的节点,然后将 pod 的资源配置单发送到 node 节点上的 kubelet 组件上。
选择主机:选择打分最高的主机,进行binding操作,结果存储到Etcd中
4、Kubelet 收到scheduler 发来的资源配置单运行 pod,运行成功后,将 pod 的运行信息返回给 scheduler,scheduler 将返回的 pod 运行状况的信息存储到 etcd 数据中心。
5、选择主机绑定成功后,会启动container, docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。
# 6、Kubernetes 中 Pod 的健康检查方式有哪些?
对 Pod 的健康检查可以通过两类探针来检查:LivenessProbe 和 ReadinessProbe。
- LivenessProbe 探针:用于判断容器是否存活(running 状态),如果 LivenessProbe 探针探测到容器不健康,则 kubelet 将杀掉该容器,并根据容器的重启策略做相应处理。若一个容器不包含 LivenessProbe 探针,kubelet 认为该容器的 LivenessProbe 探针返回值用于是“Success”。
- ReadineeProbe 探针:用于判断容器是否启动完成(ready 状态)。如果 ReadinessProbe 探针探测到失败,则 Pod 的状态将被修改。Endpoint Controller 将从 Service 的 Endpoint 中删除包含该容器所在 Pod 的 Eenpoint。
# 7、Kubernetes 自动扩容机制
分为手动和自动两种,我这里讲的是自动模式——HPA
Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据资源利用率或者自定义指标自动调整replication controller, deployment 或 replica set,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适于无法缩放的对象,例如DaemonSet。
HPA主要是对pod资源的一个计算,对当前的副本数量增加或者减少。
HPA大概是这样的,我们需要创建一个hpa的规则,设置这样的一个规则对pod实现一个扩容或者缩容,主要针对deployment,当你当前设置的资源利用率超出你设置的预值,它会帮你扩容缩容这些副本。
参考:https://blog.51cto.com/u_14143894/2458468 (opens new window)
hpa本身就是一个控制器,循环的控制器,它会不断的从metrics server(Heapster 或自定义 Metrics Server) 中去获取这个指标(CPU、内存、也可以定制QPS、TPS),判断这个预值是不是到达你设置规则的预值.
- 如果是的话,就会去执行这个scale帮你扩容这个副本
- 如果长期处于一个低使用率的情况下,它会帮你缩容这个副本
在 Kubernetes 从 1.10 版本后采用 Metrics Server 作为默认的性能数据采集和监控,主要用于提供核心指标(Core Metrics),包括 Node、Pod 的 CPU 和内存使用指标。
k8s面试题参考:https://blog.csdn.net/estarhao/article/details/114703958
