 Redis面试题
Redis面试题
我们在单机服务器,出现资源的竞争,一般使用synchronized 就可以解决,但是在分布式的服务器上,synchronized 就无法解决这个问题,这就需要一个分布式事务锁。
除此之外面试,基本会问springboot、Redis,然后都会一路再聊到分布式事务、分布式事务锁的实现。
# 1、为什么要使用Redis呢,对Redis的一些个人理解
官方解释:Redis是一个可基于内存亦可持久化的日志型、Key-Value数据库。
论持久化,我们平时使用的MySQL就足够了,那为什么还需要引入Redis呢?无法就是 :性能 。
数据获取的流程,一般是前端请求,后台先从缓存中取数据,缓存取不到则去数据库中取,数据库取到了则返回给前端,然后更新缓存,如果数据库取不到则返回空数据给前端。
那Redis的性能表现在哪方面呢——快 和 并发。
为什么快?
1)基于内存 2)单线程,避免上下文切换 3)非阻塞I/O多路复用机制 4)数据结构用的好。使用hash结构、压缩表、跳表等。
并发:
在高并发的情况下,比如说秒杀,当大量的请求都直接访问数据库,数据库会出现压力,如果使用Redis,就可以把MySQL的数据更新同步的到Redis,请求过来就可以先查Redis,没有再差数据库,减少压力。
# 2、讲一下个人对I/O多路复用机制 的理解
**“多路”指的是多个网络连接,“复用”**指的是复用同一个线程。
简单理解:
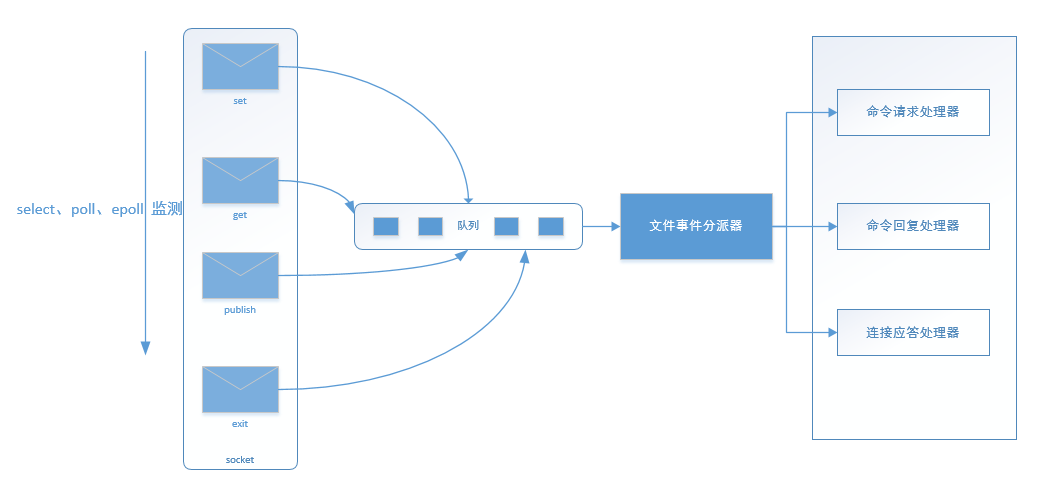
多个socket请求,socket包括很多种事件类型,有get、push、exit 等等。这些socket准备好, 将其置入队列之中 ,文件事件分派器依次去队列中取,转发到不同的事件处理器中。
引用知乎一个生动形象的例子:
作者:柴小喵 链接:https://www.zhihu.com/question/28594409/answer/52835876 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
下面举一个例子,模拟一个tcp服务器处理30个客户socket。 假设你是一个老师,让30个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
\1. 第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。这中间如果有一个学生卡主,全班都会被耽误。 这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。 \2. 第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。 \3. 第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。。。 这种就是IO复用模型,Linux下的select、poll和epoll就是干这个的。将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。 这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。
注意区分:select、poll跟epoll是不一样的。select/poll只会告诉你有人举手,不会告诉你是哪个同学举的手。
# 3、Redis的数据类型和用法
String字符串 可以为整形、浮点型和字符串,统称为元素,点赞、计数、粉丝数
Hash
一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象、用户信息
List 有序串列表,粉丝列表、消息队列。
Set 无序集合,集合成员是唯一的,这就意味着集合中不能出现重复的数据。共同关注、喜好、好友,标签。
ZSet 有序集合,集合成员是唯一的。排行榜。
# 4、redis的过期策略
# 1.定时删除
在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除 优点: 保证内存被尽快释放 缺点: 1)若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key。 2)定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
# 2.惰性删除
key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。 优点: 删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步. 缺点: 若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
# 3.定期删除
如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历,随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key,判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。(默认每个库检测20个key) 优点: 1)通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点 2)定期删除过期key--处理"惰性删除"的缺点 缺点: 1)在内存友好方面,不如"定时删除" 2)在CPU时间友好方面,不如"惰性删除"
Redis采用的策略:定期删除+惰性删除
# 5、内存淘汰机制
Redis有过期策略,假如你的Redis只能存1G的数据,你一个请求写入2G,而你也没有及时请求key,那么惰性删除就不生效了,Redis占用内存就会越来越高。
Redis可以设置内存大小:
# maxmemory <bytes>
# 设置Redis最大占用内存大小为100
maxmemory 100mb
超过了这个内存大小,就会触发内存淘汰机制
Redis有一个默认配置,这个是Redis的默认 内存淘汰机制:
# maxmemory-policy noeviction
maxmemory-policy一共有8个值,当内存不足时:
1)noeviction: 不删除,直接返回报错信息。 2)allkeys-lru:移除最久未使用(使用频率最少)使用的key。推荐使用这种。 3)volatile-lru:在设置了过期时间的key中,移除最久未使用的key。 4)allkeys-random:随机移除某个key。 5)volatile-random:在设置了过期时间的key中,随机移除某个key。 6)volatile-ttl: 在设置了过期时间的key中,移除准备过期的key。 7)allkeys-lfu:移除最近最少使用的key。 8)volatile-lfu:在设置了过期时间的key中,移除最近最少使用的key。
LRU和LFU的区别:
LRU是最近最少使用页面置换算法(Least Recently Used),也就是首先淘汰最长时间未被使用的页面!
比如有数据 1,1,1,2,2,3 此时缓存中已有(1,2) 当3加入的时候,得把前面的1淘汰,变成(3,2)
LFU是最近最不常用页面置换算法(Least Frequently Used),也就是淘汰一定时期内被访问次数最少的页!
比如有数据 1,1,1,2,2,3 缓存中有(1(3次),2(2次)) 当3加入的时候,得把后面的2淘汰,变成(1(3次),3(1次))
引申:
假如我的key没有设置expire,即没有设置过期时间。那么 volatile-lru、volatile-random、volatile-ttl 就无法执行了,和 noeviction 就一样了。
# 6、Redis的持久化机制
Redis是基于内存操作的,但它是一个支持持久化的数据库,通过持久化机制就可以把数据同步到硬盘,当Redis重启的时候就把硬盘的书籍加载到内存。 Redis支持两种持久化机制,一种是RDB,另一种是AOF,可以单独使用其中一种或将二者结合使用。
RDB持久化
RDB持久化是将当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),保存的文件后缀是.rdb;当Redis重新启动时,可以读取快照文件恢复数据。
RDB做持久化操作的时候,主线程需要调用系统的 fork() 函数,构建出一个子进程去操作;但是在子线程执行期间,父进程是阻塞的,无法响应其他请求。
所以这种RDB方式很影响Redis的性能。
AOF持久化 RDB持久化是将进程数据写入文件,而AOF是将Redis执行的每次写命令记录到单独的日志文件中。(缓冲器) 随着日志文件的越来越大,Redis也是需要fork()函数去缩小日志文件大小的。 AOF还有另外一个方法,就是刷盘策略fsync,Redis默认每隔一秒进行一次fsync调用,将缓冲器的数据写入到磁盘。 如果磁盘不稳定,fsync也是会耗时的,也会影响性能。
AOF有三种刷盘模式:
- always:把每个写命令都立即同步到aof,很慢,但是很安全
- everysec:每秒同步一次,是折中方案
- no:redis不处理,交给OS来处理,非常快,但是也最不安全
一般采用everysec策略。
Redis重启如何恢复数据呢?
Redis启动前会先检查AOF文件,不存在才会去加载RDB文件,因为AOF的数据完整性高,最多也就损失1秒的数据。
两者区别:
1、都是调用了fork()函数,期间主线程会阻塞,然后子线程执行不阻塞。
2、AOF恢复比较慢;RDB文件小,恢复快。
3、RDB是数据快照文件,AOF是命令操作的日志文件,追加写。
# 7、缓存击穿、穿透、雪崩有什么分别,如何应对?
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大(不存在的数据)。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决:
- 接口层增加校验,如用户鉴权校验,id做基础校验,比如 id<=0的直接拦截; 最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
- 另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
缓存击穿是指缓存中没有但数据库中有的数据,当一个key非常热点(类似于爆款),在不停的扛着大并发,大并发集中对这一个点进行访问;当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
解决:
- 设置热点数据永远不过期。
- 加互斥锁。
缓存雪崩是指缓存中数据大批量到过期时间,大批量数据同一时间过期,导致请求量全部请求到数据库,造成数据库宕机。
解决:
给缓存失效时间,加上一个随机值,避免大量缓存集体失效。
双缓存:缓存A和B,比如A的失效时间是20分钟,B不失效。比如从A中没读到,就去B中读,然后异步起一个线程同步到A。
# 8、Memcache与Redis的区别
1、存储方式不同,可靠性不同
memecache 把数据全部存在内存之中;Redis可以持久化到硬盘。宕机、断电 Redis可以恢复,memecache 不能,memecache 不支持数据持久化。
2、数据类型不同
memecache只有简单的字符串类型,虽然也可以缓存图片;Redis有很多种类型。
3、速度不一样
Memcache可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS,适用于最大程度扛量,100k以上的文件memcache较快。
4、存储数据大小不一样
Memcached单个key-value大小有限,一个value最大只支持1MB,而Redis最大支持512MB 。
# 9、Redis 常见性能问题和解决方案
(1) Master 最好不要做任何持久化工作,如 RDB 内存快照和 AOF 日志文件。(因为RDB生成快照是很耗性能的,这样会阻塞master,会造成master假死) (2) 如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次(这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度,所以要合理设置AOF重写机制) (3) Master 和 Slave 最好在同一个局域网内(主从复制的速度快和连接的稳定性强 ) (4) 读写分离,把请求压力分散到各个服务。
# 10、Redis分布式锁了解吗?
关键点:SETNX命令。
Redis中提供SETNX命令可以实现分布式锁。redisson也可以实现(redisson是在Redis是封装的一个jar,简单灵活),配合lua进行加锁和解锁。
将 key 的值设为 value ,当且仅当 key 不存在。 若给定的 key 已经存在,则 SETNX 不做任何动作。
RLock rLock = redissonClient.getLock(lockKey);
Boolean flag = rLock.tryLock(20, 10, TimeUnit.SECONDS);
rLock.unlock();
如果要实现分布式锁,一定要解锁。
# 11、Redis的并发竞争问题如何解决?
出现这个问题的原因:多个子系统去set一个key-value,并发情况下,可能会导致数据一致性问题。
上面第10点说的分布式锁是一种方案,利用SETNX命令。确保同一个时间,只有一个线程拿到了锁,其他则在等待。
还有一种方案就是时间戳。
参考自:孤独烟大佬的
如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC. 期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
# 12、redis 事务了解吗?
Redis也自带事务,但是和MySQL的不同,又有点类似。
Redis事务和MySQL一样,通过 begin;commit;rollback去开启和提交/回滚事务,只不过命令不一样。
具体参考:https://www.cnblogs.com/DeepInThought/p/10720132.html
# 13、双一致性问题
简单的说就是先写Redis还是先写数据库的问题。
比如:
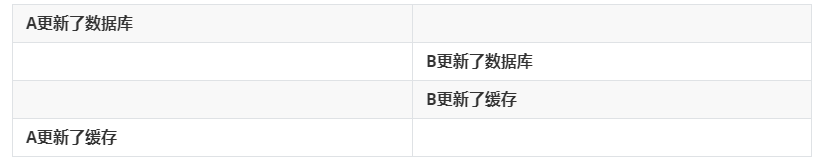
那么A就会有数据脏读问题。
如果想深入了解(这个比较复杂)可以参考这个:
https://www.cnblogs.com/rjzheng/p/9041659.html
