 Map
Map
# Map 介绍
Map<K, V>是一种键-值映射表。
不允许键重复,但是值可以重复
作用就是能高效通过key快速查找value(元素)。
我们称K(key)为键;V(value)为值
K、V 都只能是对象,不能是基本数据类型(但可以使用包装类)
使用:
import java.util.Map;
# Map 接口的API
# 1、put(k,v)
put()方法是把键-值丢进Map里面。
- 如果键值不存在,则返回
null - 如果键值存在,则返回键原来的旧值
重复放入
key-value并不会有任何问题,但是一个key只能关联一个value
# 2、get(k)
put()方法是通过一个键获取一个值。
- 如果键不存在,则返回一个
null - 如果键存在,则键对应的值。
# 3、size()
返回Map的大小。
# 4、isEmpty()
判断一个Map是否为空,如果为空,相当于 size() =0
# 5、containsKey(k)
是否存在某个k
还有类似的containsValue(),返回是否存在某个值。
Map还有很多API,大家可以到java.uti.Map查看。
# Map接口的实现类
Map是一个接口,既然是接口,那就必须有实现类才行,常见的Map实现类有三个:
- HashMap
- HashTable
- TreeMap
# 1、HashMap
HashMap 的特点是 **key、value值 均可 为null **
HashMap 是无序的,即不会记录插入的顺序。
Map<Integer,String> map = new HashMap<>();
map.put(1,"五菱宏光");
map.put(2,"宝马");
map.put(3,"奥迪");
map.put(null, null);
System.out.println(map.get(1)); //五菱宏光
System.out.println(map.put(1, "帅气的五菱宏光")); //五菱宏光
System.out.println(map.get(1)); //帅气的五菱宏光
System.out.println(map.get(null)); //null
System.out.println(map.size()); // 3
System.out.println(map.isEmpty()); // false
System.out.println(map.containsKey(1)); //true
System.out.println(map.containsValue("奥迪")); //true
Map的值可以是一个Object对象,所以还可以这样使用:
class Car {
private String number;
private String carName;
Car(String number, String carName) {
this.number = number;
this.carName = carName;
}
}
public class MapTest {
public static void main(String[] args) {
Car wuLingHongGuang = new Car("粤M88888", "五菱宏光");
Car baoMa = new Car("粤M66666", "宝马");
//Car 做为整一个对象
Map<Integer, Car> map = new HashMap<>();
map.put(1, wuLingHongGuang);
map.put(2, baoMa);
}
}
下面这种写法也是可以的:
Map map = new HashMap();
HashMap hashMap = new HashMap();
这种没有声明 Map<String,String> 的泛型。在获取值的时候,会返回一个Object类型的对象,而不是返回一个初始化指定的泛型。
eg:
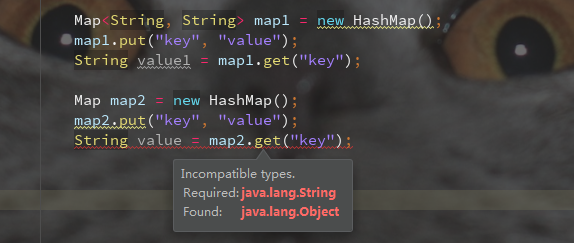
无法从Object转到String。
所以在使用集合的时候,尽量指定泛型,否则很可能就会报类型转换错误。
HashMap 是一个重点,也是日常开发中使用比较多的数据结构,HashMap的原理:
# 2、HashTable
HahTable对象的key、value值均不可为null。
Map<Integer, String> hashtable = new Hashtable<>();
# 3、TreeMap
TreeMap是有序的,会记录插入的顺序。
TreeMap 底层为数据结构为红黑树,TreeMap 实现 SortMap 接口,能够把它保存的记录根据键排序(默认按键值升序排序,也可以指定排序的比较器)
TreeMap对象的key不可以为null、value值可为null。
因为TreeMap要实现Comparator 接口进行比较,所以key不可以为null
Map<Integer, String> treeMap = new TreeMap<>();
# 4、LinkedHashMap
保存了记录的插入顺序,在用 Iterator 遍历时,先取到的记录肯定是先插入的;
遍历比 HashMap 慢。
LinkedHashMap 用的比较少,一般情况下很少使用。
# 5、ConcurrentHashMap
从名字就可以看出来ConcurrentHashMap是HashMap的线程安全版。
同HashMap相比,ConcurrentHashMap不仅保证了访问的线程安全性,而且在效率上与HashTable相比,也有较大的提高。除了加锁,原理上和HashMap无太大区别。
另外,HashMap 的键值对允许有null,但是 ConcurrentHashMap都不允许。
# HashMap 和 Hashtable 的区别:
相同点:
都是实现来Map接口(hashTable 还实现了Dictionary 抽象类)
区别:
- 历史原因:Hashtable 是基于陈旧的 Dictionary 类的,HashMap 是 Java 1.2 引进的 Map 接口
的一个实现,HashMap把Hashtable 的contains方法去掉了,改成containsvalue 和containsKey。因为contains方法容易让人引起误解。
同步性:Hashtable 的方法是 Synchronize 的,线程安全;而 HashMap 是线程序不安全的,不是同步的。所以只有一个线程的时候使用hashMap效率要高。
值:只有 HashMap 可以让你将空值NULL作为一个表的条目的 key 或 value,Hashtable 不允许。
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
HashMap扩容时是当前容量翻倍即:capacity2,Hashtable扩容时是容量翻倍+1即:capacity2+1。
另外:
sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
HashMap可以通过下面的语句进行同步(如果非要使用HashMap):
Map m = Collections.synchronizeMap(hashMap);
# HaspMap与TreeMap的区别:
1、 HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
2、在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
为什么说HashMap是无序的?TreeMap是有序的
以HashMap为例,假设我们放入"1","2","3"这3个key,遍历的时候,每个key会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历的输出顺序都是不同的。
如果要保证插入的顺序和遍历的顺序,建议选用LinkedHashMap,可以保证put的顺序和遍历的顺序是一样的。
# 总结一下使用选择
一般情况下,使用最多的是 HashMap。
HashMap:在 Map 中插入、删除和定位元素时;
TreeMap:在需要按自然顺序或自定义顺序遍历键的情况下;
LinkedHashMap:在需要输出的顺序和输入的顺序相同的情况下。
# 奇淫异巧
# 1、匿名函数初始化Map
初始化一个Map可以这样写:
Map<String, String> params = new HashMap<String, String>() {
{
put("key", "value");
put("key1", "value");
}
};
# 2、Map的遍历
class Test{
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "五菱宏光");
map.put(3, "奥迪");
map.put(2, "宝马");
// 遍历方法1
for (Integer key : map.keySet()) {
String value = map.get(key);
System.out.println(key + " = " + value);
}
// 遍历方法2 常用
for (Map.Entry<Integer, String> entry : map.entrySet()) {
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " = " + value);
}
//如果是jdk1.8及以上,可以使用lambda表达式
map.forEach((key, value) -> {
System.out.println(key + " = " + value);
});
//3、遍历方法3 Iterator 迭代器 ,常用
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " = " + value);
}
//通过键来遍历
Iterator iterator1 = map.keySet().iterator();
while (iterator1.hasNext()) {
System.out.println(iterator1.next());
}
//通过值来遍历
Iterator iterator2 = map.values().iterator();
while (iterator2.hasNext()) {
System.out.println(iterator2.next());
}
//4、遍历方法3 通过Map.values()遍历所有的value,但不能遍历key
for (String value : map.values()) {
System.out.println("value: " + value);
}
}
}
# 总结:
1、hashtable是早起java类库提供的一个哈希表实现,本身是同步的,不支持null键和空值,由于同步导致的性能开销,现在已经很少被使用了
2、hashmap是应用更加广泛的哈希表实现,应为大体和hashtable一致,不同点是hashmap支持null键和空值,而且不是同步的。他的put和get方法,可以达到常数时间的性能,是绝大多数利用键值对存取场景的首选
3、treemap是基于红黑树实现的一种提供顺序访问的map,与hashmap不同的是的get和putremove方法,都是log(n)的时间复杂度,具体顺序可以由指定的comparator来决定,默认是按照升序排列。
