 Kafka的入门
Kafka的入门
https://www.cnblogs.com/sujing/p/10960832.html
https://blog.csdn.net/suifeng3051/article/details/48053965
# 1、kafka的架构
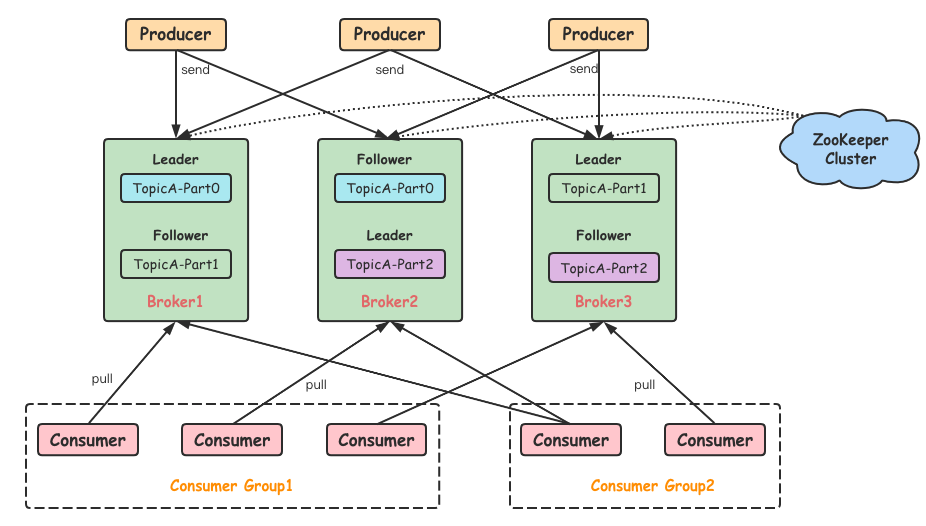
Producer:Producer即生产者,消息的产生者,是消息的入口。
kafka cluster:
Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message:每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。 - Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
一个 Topic 中的一个分区只能被同一个 Consumer Group 中的一个消费者消费,其他消费者不能进行消费。这里的一个消费者,指的是运行消费者应用的进程,也可以是一个线程。
# 注意点:
1)Topic 与 Partition
在 Kafka 中消息是以 Topic 为单位进行归类的,Topic 在逻辑上可以被认为是一个 Queue,Producer 生产的每一条消息都必须指定一个 Topic,然后 Consumer 会根据订阅的 Topic 到对应的 broker 上去拉取消息。
为了提升整个集群的吞吐量,Topic 在物理上还可以细分多个分区,一个分区在磁盘上对应一个文件夹。由于一个分区只属于一个主题,很多时候也会被叫做主题分区(Topic-Partition)。
2)Leader 和 Follower
一个分区会有多个副本,副本处于不同 broker 中,副本之间是一主(Leader)多从(Follower)的关系,生产者与消费者只和 Leader 副本进行交互,而Follower 副本只负责消息的同步,不能与外界进行交互,当 Leader 副本出现故障时,会从 Follower 副本中重新选举新的 Leader 副本对外提供服务。
# 发送流程:
首先指定消息发送到哪个
Topic。选择一个
Topic的分区partitiion,默认是轮询来负载均衡。也可以指定一个分区
key,根据key的hash值来分发到指定的分区。也可以自定义
partition来实现分区策略。找到这个分区的
leader partition。与所在机器的
Broker的socket建立通信。发送
Kafka自定义协议格式的请求(包含携带的消息、批量消息)。
# 2、kafka和Pulsar
**Apache Kafka(简称Kafka)**是由LinkedIn公司开发的分布式消息流平台,于2011年开源。Kafka是使用Scala和Java编写的,当下已成为最流行的分布式消息流平台之一。Kafka基于发布/订阅模式,具有高吞吐、可持久化、可水平扩展、支持流数据处理等特性。
**Apache Pulsar(简称Pulsar)**是雅虎开发的“下一代云原生分布式消息流平台”,于2016年开源,目前也在快速发展中。Pulsar集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
Kafka与Pulsar都具有(或追求)以下特性
- **高吞吐、低延迟:**它们都具有高吞吐量处理大规模消息流的能力,并且能够低延迟处理消息。这也是大多数消息流平台追求的目标。
- **持久化、一致性:**Kafka与Pulsar都支持将消息持久化存储,并提供数据备份(副本)功能,保证数据安全及数据一致性,它们都是优秀的分布式存储系统。
- **高可扩展性(伸缩性):**Kafka与Pulsar都是分布式系统,会将数据分片存储在一组机器组成的集群中,并支持对集群进行扩容,从而支持大规模的数据。
- **故障转移(容错):**Kafka与Pulsar支持故障转移,即集群中某个节点因故障下线后,并不会影响集群的正常运行,这也是优秀的分布式系统的必备功能
流计算应用不断地从Kafka与Pulsar中获取流数据,并对数据进行处理,最后将处理结果输出到Kafka与Pulsar中(或其他系统)。
流计算应用通常需要根据业务需求对流数据进行复杂的数据变换,如流数据聚合或者join等。为此,Kafka提供了Kafka Streams模块,Pulsar提供了Pulsar Functions模块,它们都可以实现流计算应用。
另外,Kafka与Pulsar也可以与流行的Spark、Flink等分布式计算引擎结合,构建实时流应用,实时处理大规模数据。
