 序列化与反序列
序列化与反序列
# 1、序列化和反序列化是什么?
如果你看过某些类的源码或者公司的项目,有一些类是实现 Serializable 接口,同时还要显示指定 serialVersionUID 的值。
例如String类:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
先来解释一下这两个概念:
- 序列化:把对象转换为字节序列的过程称为对象的序列化.
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化.
太复杂了?
再简单点说:
序列化是指把一个Java对象变成二进制内容,本质上就是一个byte[]数组。
为什么要把Java对象序列化呢?
因为序列化后可以把byte[]保存到文件中,或者把byte[]通过网络传输到远程,这样,就相当于把Java对象存储到文件或者通过网络传输出去了。
毕竟网络传输我们看得到的字符、对象,它是传输字节的,所以需要序列化;传输完成要还原,就要反序列化。
有序列化,就有反序列化,即把一个二进制内容(也就是byte[]数组)变回Java对象。有了反序列化,保存到文件中的byte[]数组又可以“变回”Java对象,或者从网络上读取byte[]并把它“变回”Java对象。
# 2、序列化和反序列化的例子
public class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
serializeStudent();
deserializeStudent();
}
//序列化
static void serializeStudent() throws IOException, ClassNotFoundException {
FileOutputStream fos = new FileOutputStream("F:\\HaC.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
Student student1 = new Student("HaC", "HelloCoder", 30);
oos.writeObject(student1);
oos.flush();
System.out.println("Student 对象序列化成功!");
oos.close();
}
static void deserializeStudent() throws IOException, ClassNotFoundException {
//反序列化
FileInputStream fis = new FileInputStream("F:\\HaC.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
Student student2 = (Student) ois.readObject();
System.out.println(student2.getUserName() + " " +
student2.getPassword() + " " + student2.getYear());
System.out.println("Student 对象反序列化成功!");
}
}
@Data
@AllArgsConstructor
class Student implements Serializable{
private static final long serialVersionUID = 3608451818006447637L;
private String userName;
private String password;
private String year;
//省略get、set
}
可以看到生成了一个打开是乱码的二进制文件:

其实这个例子就是序列化和反序列化的一个小过程,JVM通过序列化把对象写到文件,再通过反序列化从文件中读取数据,把数据转成一个对象。
看到控制台输出也是正常的:
Student 对象序列化成功!
HaC HelloCoder 30
Student 对象反序列化成功!
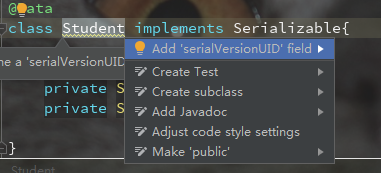
IDEA可以设置生成 serialVersionUID:
然后双击选中你的类,按下 Alt + Enter:
# 2.1、序列化场景作用
所以序列化和反序列化的作用是:
1、把对象转成JSON、xml 的时候,往往这些接口、方法 都实现了序列化,因为网络传输也是一个二进制的过程,需要进行转换。
所以只要我们对内存中的对象进行持久化或网络传输, 这个时候都需要序列化和反序列化.
2、还有一个作用就是把对象的字节序列永久地保存到硬盘上 ,比如通过mybatis可持久化到MySQL,也是实现了序列化的。
比如:
<insert id="insertUser" parameterType="org.yudianxx.bean.User">
INSERT INTO user(name, age) VALUES (#{name}, #{age})
</insert>
实际上我们并不是将整个对象持久化到数据库中, 而是将对象中的属性持久化到数据库中, 而这些属性都是实现了 Serializable 接口的基本属性。
我们场景的RPC框架,比如dubbo,在网络传输数据的时候,也是进行了序列化,你可以理解为这是一种编码/解码。
总之一句话,只要我们对内存中的对象进行持久化或网络传输, 都需要进行序列化和反序列化。
# 3、为什么要实现 Serializable 接口还要指定serialVersionUID的值?
在 Java 中实现了 Serializable 接口后, JVM 会在底层帮我们实现序列化和反序列化,如果你实现该接口,你也可以自己自定义一个,就是有点复杂,这里不展开。
如果不显示指定 serialVersionUID, JVM 在序列化时会根据属性自动生成一个 serialVersionUID, 然后与属性一起序列化,再进行持久化或网络传输。
在反序列化时,JVM 会再根据属性自动生成一个新版 serialVersionUID,然后将这个新版 serialVersionUID 与序列化时生成的旧版 serialVersionUID 进行比较,如果相同则反序列化成功, 否则报错.
如果显示指定了 serialVersionUID, JVM 在序列化和反序列化时仍然都会生成一个 serialVersionUID, 但值为我们显示指定的值,这样在反序列化时新旧版本的 serialVersionUID 就一致了.
接上面的例子,我不生成serialVersionUID,反序列化也是没有问题的,但如果我指定了不一致的serialVersionUID ,或者加了新的属性:
class Student implements Serializable {
// private static final long serialVersionUID = 1L;
private String userName;
private String password;
private int year ;
private int age;
再调用deserializeStudent() 反序列化方法时就会报错:
Exception in thread "main" java.io.InvalidClassException: com.yudianxx.basic.序列化.Student; local class incompatible: stream classdesc serialVersionUID = -2548470143096162701, local class serialVersionUID = -9192788448472055372
可以看到有一个默认的serialVersionUID。
还有一种情况就是,假如你不实现Serializable接口,在反序列化的时候也是会报错的:
class Student {
private String userName;
private String password;
private int year ;
}
报错NotSerializableException:
Exception in thread "main" java.io.NotSerializableException: com.yudianxx.basic.序列化.Student
通过这个例子你就大概知道,反序列化是和类和属性有关,就像秘钥和公钥一样,只有正确的serialVersionUID和类匹配,才能反序列化。
# 3、序列化的其他特性
# 1、static 属性不会被序列化
# 2、transient 修饰的属性,也不会被序列化
当某个字段被声明为transient后,默认序列化机制就会忽略该字段
这里我举个例子:
class Student implements Serializable {
private static final long serialVersionUID = 3608451818006447637L;
private String userName;
private static String password = "123456";
private transient int year = 24;
//省略get set
}
我先调用serializeStudent() 进行序列化。
serializeStudent();
// deserializeStudent();
然后再调用deserializeStudent()
// serializeStudent();
deserializeStudent();
可以看到输出:
HaC 123456 0
Student 对象反序列化成功!
在序列化写入文件的时候是 Student student1 = new Student("HaC", "HelloCoder", 30);
反序列化就有问题。在序列化时,因为它不会把序列化,所以反序列化只能拿到默认定义的值。
# 4、Java序列化的缺点
上面提到RPC框架也用到了序列化,你可以理解为这是一种编码和解码的过程,比如A要向B发送数据,A要把数据序列化才能传到B(网络传输会将对象转换成字节流传输),否则字符串是无法解析的(Java的String字符串是实现了序列化的)。
Java的序列化缺点有:
# 4.1、无法跨语言
过Java的原生Serializable接口与ObjectOutputStream实现的序列化,只有java语言自己能通过ObjectInputStream来解码,其他语言,如C、C++、Python等等,都无法对其实现解码。
所以你在和跨语言的程序通信,就不能用java序列化去做了。
# 4.2、性能差
java序列化后的字节的大小比二进制编码还要大。如果我们是进行网络传输,相对占用的带宽就更多,也会影响系统的性能。
因为Java的序列化不好用,所以市面上也衍生出了很多序列化(编码、解码)工具,比如:Protobuf、Thrift、JSON、xml。
# 5、结论
1、网络传输、对象转换一定要使用序列化
2、实现这个Serializable 接口的时候,一定要给这个 serialVersionUID 赋值
3、static 、transient 修饰的属性不会反序列化。
