 Redis为什么要使用单线程,新版本为什么引入多线程?
Redis为什么要使用单线程,新版本为什么引入多线程?
这篇文章不是简单的讲述单线程的好处,而是为了说明Redis为什么要采用单线程的原因。
官方测试,在单线程处理情况下,Redis读速度可达到11万次/s,写速度达到8.1万次/s。
Redis在4.0版本引入了Lazy Free,那什么是Lazy Free呢?
Redis 6.0 推出之后,采用了多线程,那问题来了,这个多线程和以前的单线程有区别吗?为什么又突然引入了多线程?
还有就是Redis我们知道它是多路复用技术著称。
本文带着这些问题来探讨一下。
# 1、Redis单线程原理
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件:
文件事件:Redis服务器通过套接字与客户端(或者其他Redis服务器)进行连接,而文件事件就是服务器对套接字操作的抽象;服务器与客户端的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作,比如连接accept,read,write,close等;
时间事件:Redis服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象,比如过期键清理,服务状态统计等。
以上部分引自:
https://juejin.cn/post/6928407842009546766,感谢蓝同学的图
EventLoop是一个时间轮询器,它会轮询I/O事件表,文件事件表就绪,就会优先处理文件事件,然后再处理时间事件。
以上都是单线程操作(红色箭头)。
此外,下图会讲到,Redis基于Reactor模式开发了自己的I/O事件处理器,也就是文件事件分派器,Redis在I/O事件处理上,采用了I/O多路复用技术,同时监听多个套接字,并为套接字关联不同的事件处理函数,通过一个线程实现了多客户端并发处理。
# 2、Redis的多路复用
上图可能没讲到多路复用,下面再详细画一下这个 I/O 事件表、文件事件分配器
**“多路”指的是多个网络连接,“复用”**指的是复用同一个线程。
简单理解:
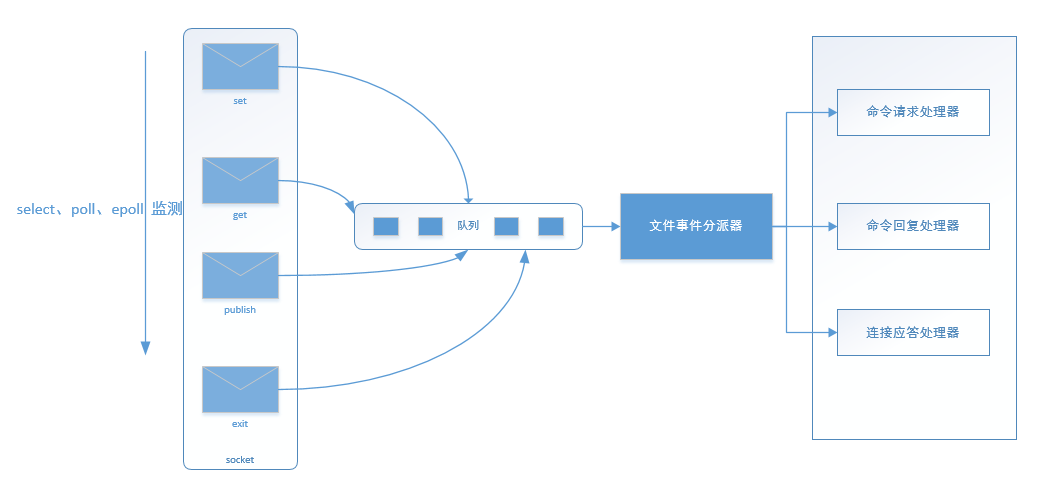
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件( I/O 事件表)的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
多个socket请求,socket包括很多种事件类型(I/O事件),有get、push、exit 等等。这些socket准备好, 将其置入队列之中 ,文件事件分派器依次去队列中取,转发到不同的事件处理器中。
所以以上的多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗)
结合以上两点来看,所以得出的结论是 Redis 单线程已经足够应对常用业务的并发量了,而且采用多路复用技术,已经十分高效了。
除此之外,我在Redis的官方文档中找到,作者是这样说的:

简单的说就是:没必要,单线程已经足够解决你们这些渣渣并发的业务了。
当然,Redis快可不止单线程、多路复用的原因,还有以下:
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。
2、数据结构简单,对数据操作也简单,如SDS、哈希表、跳表都有很高的性能。
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU
# 3、Redis4.0 引入Lazy Free机制
Lazy Free,又称为懒惰删除。
Lazy free可译为惰性删除或延迟释放;当删除键的时候,redis提供异步延时释放key内存的功能,把key释放操作放在bio(Background I/O)单独的子线程处理中,减少删除big key对redis主线程的阻塞。有效地避免删除big key带来的性能和可用性问题。
因为Redis是单线程的,总会有不可避免的瓶颈问题。
假如客户端向Redis发送一条耗时较长的命令,比如删除一个100万个字段的hash键,或者执行flushdb,flushall操作,Redis服务器需要回收大量的内存空间,其他请求完全被阻塞,而导致服务器卡住好几秒,对负载较高的缓存系统而言将会是个灾难、对于业务来说也是不可接受的。
为了解决这个问题,在Redis 4.0版本引入了Lazy Free,将慢操作异步化,这也是在事件处理上向多线程迈进了一步。
Redis4.0新增了非常实用的lazy free特性,从根本上解决Big Key(主要指定元素较多集合类型Key)删除的风险。
UNLINK是DEL的异步删除版本,UNLINK命令与DEL阻塞删除不同,UNLINK在删除集合类键时,如果集合键的元素个数大于64个,会把真正的内存释放操作,给单独的BackgroundIO线程来操作,有实验表明使用UNLINK命令删除一个大键mylist, 它包含200万个元素,但用时只有数毫秒。
通过对FLUSHALL/FLUSHDB添加ASYNC异步清理选项,redis在清理整个实例或DB时,操作也都是异步的,有实验数据表明异步清理200w数据耗时也只有数毫秒。
综上可知,采用UNLINK、FLUSHALL、FLUSHDB代替之前的阻塞删除命令可以使处理相同数据的耗时从传统秒级、甚至分钟级降低到目前的微妙,毫秒级,确实是个巨大的飞跃,或许这也是Redis直接从3.x飞跃到4.0的原因。
初始化三个后台线程,以及相应的锁、条件变量、任务队列等变量。三个后台线程分别用于:
- BIO_CLOSE_FILE对应的关闭文件描述符线程
- BIO_AOF_FSYNC对应的aof持久化冲刷磁盘线程
- BIO_LAZY_FREE对应的异步惰性删除线程
这三个线程被称为BIO线程(Background I/O线程)
有兴趣的可以了解一下Redis的删除策略:Redis的过期策略和内存淘汰机制 (opens new window)
# 4、Redis6.0 引用的多线程
关于单线程的问题,其实Redis并不是所有操作都是单线程的,比如说持久化写入RDB和AOF就是就会fork一个子进程去操作的,可以参考:Redis的持久化机制,RDB和AOF (opens new window)
所以新版本Redis 6.0中的多线程,也只是针对处理网络请求过程采用了多线程,而数据的读写命令,仍然是单线程处理的。
为什么还需要引入多线程呢?
主要是因为Redis有更高的追求。
为了以防更高的QPS
总有超过Redis承受压力的业务,为了提示性能,目前大部分的做法就是做Redis集群,但是这样消耗的资源的很大的,所以提高单机Redis的性能是最佳的。
官方说明Redis的性能瓶颈在网络IO,而不是在CPU(即线程),上面介绍过 ,Redis是采用I/O多路复用技术,但是I/O多路复用技术是属于同步阻塞型IO模型,所以它也是会出现阻塞的可能。
在上图中,我们以select函数的处理过程为例:
从上图我们可以看到,在多路复用的IO模型中,在处理网络请求时,调用 select (其他函数同理)的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,此处可能会成为瓶颈。
虽然现在很多服务器都是多个CPU核的,但是对于Redis来说,因为使用了单线程,在一次数据操作的过程中,有大量的CPU时间片是耗费在了网络IO的同步处理上的,并没有充分的发挥出多核的优势。
如果能采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
所以,Redis 6.0采用多个IO线程来处理网络请求,网络请求的解析可以由其他线程完成,然后把解析后的请求交由主线程进行实际的内存读写。提升网络请求处理的并行度,进而提升整体性能。
但是,Redis 的多 IO 线程只是用来处理网络请求的,对于读写命令,Redis 仍然使用单线程来处理,自然也不会出现并发问题。
以上部分参考自:https://juejin.cn/post/6939689834537549861
# 总结
# 1、为什么使用单线程?
因为单线程足已应对业务,而且多线程带来了锁的问题、上下文切换也是得不偿失的。主要还是结合以下一起提升了Redis的性能:
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。
2、数据结构简单,对数据操作也简单,如SDS、哈希表、跳表都有很高的性能。
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU
4、多路I/O复用技术
# 2、为什么引入多线程?
Redis4.0 引用BIO线程进行惰性删除,极大地减少主线阻塞时间。从而减少删除导致性能和稳定性问题。
Redis6.0引入多多个IO线程来处理网络请求,可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
但是读写操作还是单线程的,这个并未改变。
