 MySQL的架构和执行流程
MySQL的架构和执行流程
# MySQL的架构和执行流程是什么样的?
我们程序员在使用MySQL的时候,通过一个JDBC就可以连接MySQL进行CURD了,但是背后的细节也是需要我们知道的。
首先对MySQL进行连接的时候,也是走的TCP建立连接,而一个系统,可以和多个MySQL进行连接;一个MySQL也可以被多个系统连接,而且连接数还能有多个。
随着连接数的越来越多,管理起来就很麻烦,而且每次都要建立连接、关闭连接,开销也很大,所以就诞生了譬如 Druid 这种连接池的jdbc工具。
# 1、先说select的过程:
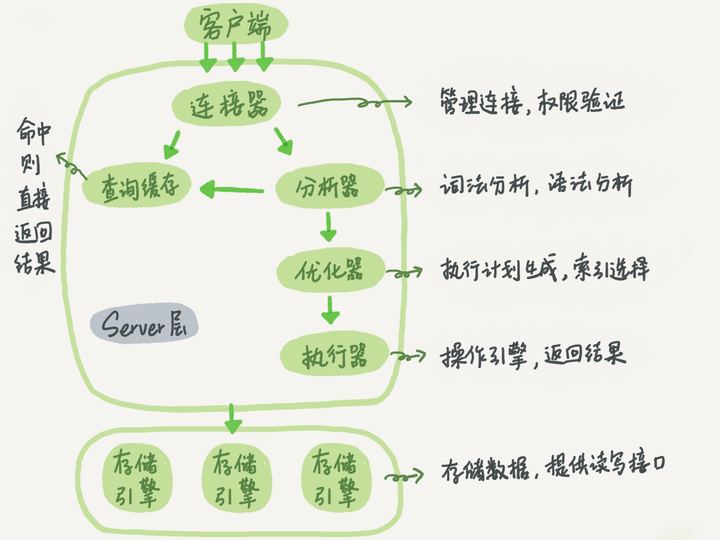
- 客户端通过TCP连接发送连接请求到mysql连接器,连接器会对该请求进行权限验证及连接资源分配
- 查缓存。(当判断缓存是否命中时,MySQL不会进行解析查询语句,而是直接使用SQL语句和客户端发送过来的其他原始信息。所以,任何字符上的不同,例如空格、注解等都会导致缓存的不命中。)
- 语法分析(SQL语法是否写错了)。 如何把语句给到预处理器,检查数据表和数据列是否存在,解析别名看是否存在歧义。
- 优化。是否使用索引,生成执行计划。(注意,这一步仅仅是生成执行计划,还没真正执行SQL)
- 交给执行器,将数据保存到结果集中,同时会逐步将数据缓存到查询缓存中,最终将结果集返回给客户端。
# 2、update、insert、delete的过程
更新语句执行会复杂一点。需要检查表是否有排它锁,写binlog,刷盘,是否执行commit。
所以MySql架构分为Server层与存储引擎层,连接管理、解析与优化这些并不涉及读写表数据的组件划分到Server层(公用层),读写表数据而是交给存储引擎层(多态层)来做;就好像一个接口一样,由不同的存储引擎接口实现读写。

上次更新: 2026-04-28 13:59:11