 Java集合类面试题
Java集合类面试题
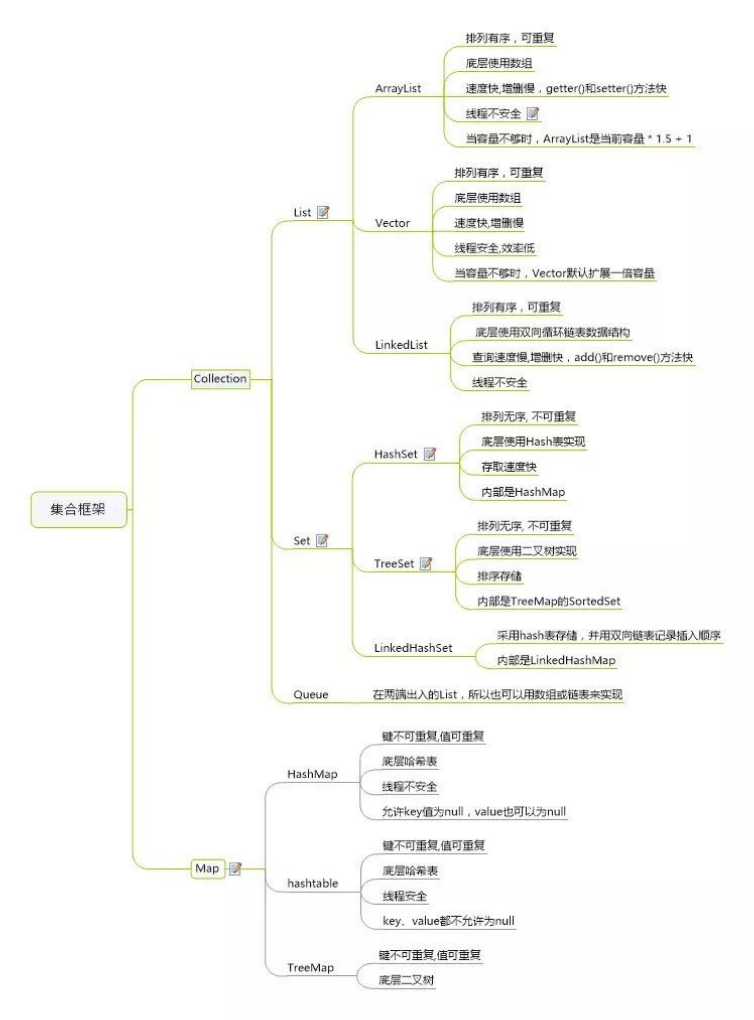
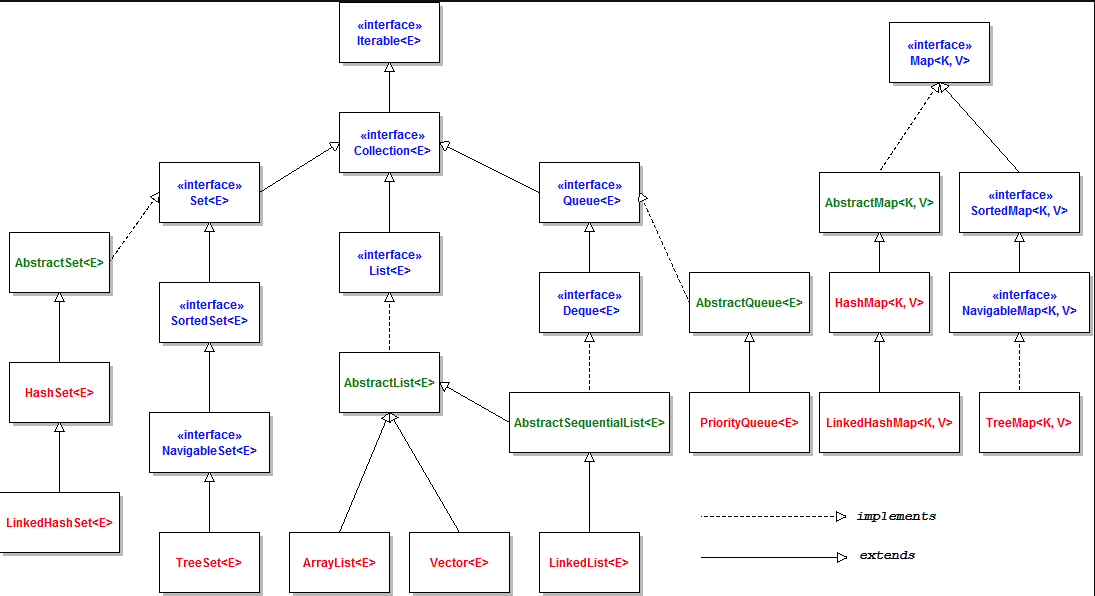
# 1、常见的集合有哪些?
线程安全:
Vector、HashTable、StringBuffer
线程不安全:
HashMap、TreeMap、HashSet、ArrayList、LinkedList
List有序,set无序,map无序,queue消息阻塞队列。
# 2、 Arraylist与 LinkedList 异同
Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向循环链表数据结构;
ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。插入末尾还好,如果是中间,则(add(int index, E element))接近O(n);LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。
LinkedList 不支持高效的随机元素访问,而ArrayList 实现了RandmoAccess 接口,所以有随机访问功能。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。所以ArrayList随机访问快,插入慢;LinkedList随机访问慢,插入快。
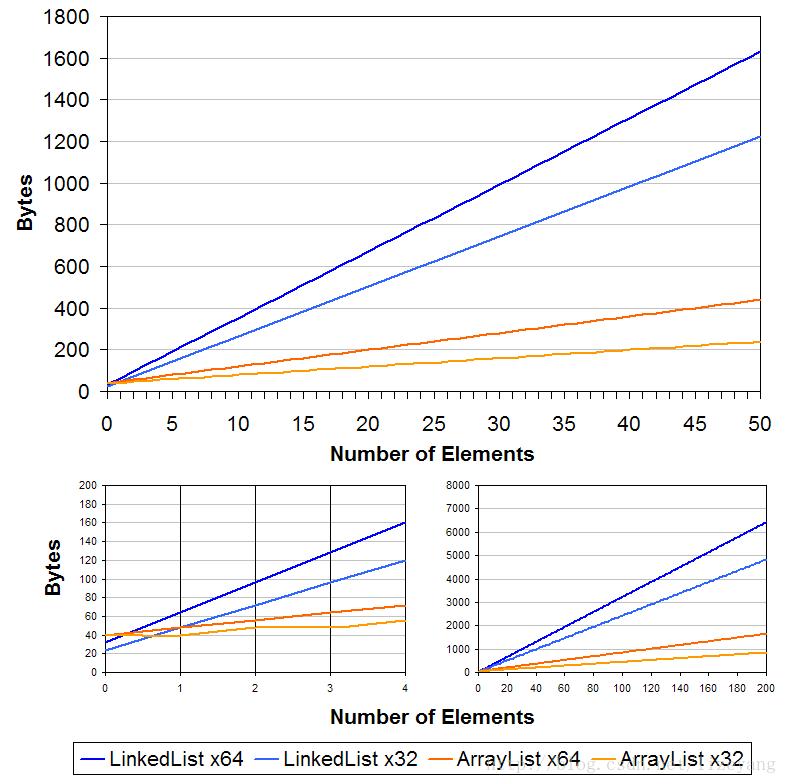
ArrayList的 空间浪费 主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱地址以及数据)。
占用空间:
一般来说LinkedList的占用空间更大,因为每个节点要维护指向前后地址的两个节点。
但也不是绝对,如果刚好数据量超过ArrayList默认的临时值时,ArrayList占用的空间也是不小的,因为扩容的原因会浪费将近原来数组一半的容量。
不过,因为ArrayList的数组变量是用transient关键字修饰的,如果集合本身需要做序列化操作的话,ArrayList这部分多余的空间不会被序列化。
transient 修饰的成员变量,在类的实例对象的序列化处理过程中会被忽略。
借用网上一张图:
# 3、 HashMap 和 Hashtable 的区别:
相同点:
- 都是实现来Map接口(Hashtable 还实现了Dictionary 抽象类)。
不同点:
| 维度 | Hashtable | HashMap | 说明 |
|---|---|---|---|
| 历史背景 | 基于Dictionary类(JDK 1.0遗留类) | Map接口实现(JDK 1.2引入) | HashMap废弃了Dictionary,且将contains方法优化为containsKey和containsValue,避免语义歧义 |
| 线程安全 | 线程安全(方法级synchronized) | 线程不安全(非同步) | 单线程下HashMap性能更优;多线程需用ConcurrentHashMap替代Hashtable |
| Null值 | 不允许 key或value为null | 允许 1个null key,多个null value | Hashtable插入null直接抛NullPointerException |
| 初始容量 | 11 | 16 | - |
| 扩容机制 | 2n + 1(容量翻倍+1) | 2n(容量翻倍,左移一位) | Hashtable设计为素数容量(或奇数)以优化散列,HashMap使用2的幂次方简化位运算 |
| 底层结构 | 数组 + 链表 | 数组 + 链表 + 红黑树(JDK 8+) | Hashtable链表无限长;HashMap当链表长度≥8且数组长度≥64时,链表转为红黑树(查询O(n) → O(log n)) |
HashMap可以通过下面的语句保证线程安全:
Map m = Collections.synchronizeMap(hashMap);
或者改用 ConcurrentHashMap
# 4、 HashSet 和 HashMap 区别
HashSet 底层就是基于 HashMap 实现的。只不过HashSet里面的HashMap所有的value都是同一个Object而已,因此HashSet也是非线程安全的。
这个设计是经典的"组合复用"原则的体现。
| 维度 | HashMap | HashSet |
|---|---|---|
| 实现的接口 | 实现 Map 接口 | 实现 Set 接口 |
| 存储内容 | 键值对 (Key-Value) | 仅对象 (只有Key,没有Value) |
| 添加元素方法 | 调用 put(key, value) 方法 | 调用 add(e) 方法 |
| HashCode 计算 | 根据**键(Key)**计算HashCode | 根据成员对象计算HashCode。两个不同对象可能计算相同HashCode,需配合equals()判重 |
| 判重机制 | 键唯一:通过 hashCode() 和 equals() 判断Key是否重复 | 元素唯一:通过 hashCode() 和 equals() 判断元素是否已存在 |
| 速度/性能 | 相对较快:直接根据Key定位Value(O(1)理想复杂度) | 相对较慢:底层实际使用HashMap,但只使用Key,Value为常量占位,逻辑相同但封装了一层 |
| 底层原理 | 底层是数组+链表+红黑树 | 底层实际上是HashMap:存值时将元素作为HashMap的Key,Value统一为一个固定的Object常量 |
# 5、ConcurrentHashMap和Hashtable的区别
JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类,都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
# 6、Set和List的区别
| 维度 | Set | List |
|---|---|---|
| 数据顺序 | 无序:元素存取顺序不一定一致(部分实现类如TreeSet可排序,但非插入顺序) | 有序:元素存取顺序一致(按插入顺序排列) |
| 数据重复 | 不允许重复:元素唯一,最多包含一个null | 允许重复:可包含多个null元素 |
| 底层结构 | 基于 HashMap 实现(元素作为Key) | 基于 数组(如ArrayList)或 双向链表(如LinkedList)实现 |
| 性能特点 | 删除/插入快:无需移动元素;查询慢:需遍历(HashSet O(1) 实际是特例,指contains依靠hash定位快) | 查询快(数组实现):下标直接访问 O(1);删除/插入慢:需移动元素(链表实现在头尾操作快,但中间操作慢) |
| 常用实现类 | HashSet(哈希表,最快)、TreeSet(红黑树,可排序)、LinkedHashSet(链表维护插入顺序) | ArrayList(数组,查询快)、LinkedList(链表,增删快,首尾操作)、Vector(线程安全,已过时) |
| Null值存储 | 最多一个null | 可多个null |
# 7、 ArrayList 与 Vector 的区别:
共同点: 都实现了List接口,都是有序的集合,我们可以按位置的索引号取出元素,其中数据都是可以重复的,这是与hashSet最不同的,hashSet不可以按照索引号去检索其中的元素,也不允许有重复的元素。
| 维度 | ArrayList | Vector |
|---|---|---|
| 线程安全 | 线程不安全(非同步) | 线程安全(方法级synchronized) |
| 适用场景 | 单线程环境:效率更高 | 多线程环境:无需额外同步代码,但性能较低(现代并发推荐CopyOnWriteArrayList) |
| 扩容机制 | 扩容为原来的 1.5 倍(1.5倍扩容是时间和空间的折中:扩容太频繁影响性能,扩容太大浪费内存) | 扩容为原来的 2 倍(可自定义增长量) |
| 初始容量 | 默认 10(懒加载:JDK 8+ 首次添加时创建数组) | 默认 10(构造时立即创建数组) |
| 容量设置 | 可设置初始容量,但无法设置扩容增量 | 可设置初始容量和扩容增量(capacityIncrement) |
| 遗留性 | JDK 1.2 引入,非遗留类 | JDK 1.0 遗留类,官方推荐优先使用 ArrayList |
| 性能 | 较高:无同步开销,适合大多数场景 | 较低:同步开销大,方法级锁粒度粗 |
| 迭代器 | fail-fast:迭代过程中检测到修改会抛出ConcurrentModificationException | fail-fast(同ArrayList),但elements()返回的旧式枚举非fail-fast |
# 8、HaspMap与TreeMap的区别:
| 维度 | HashMap | TreeMap |
|---|---|---|
| 底层结构 | 哈希表(数组+链表+红黑树,JDK 8+) | 红黑树(自平衡的二叉查找树) |
| 元素顺序 | 无序:不保证元素的顺序(甚至顺序可能随时间变化) | 有序:元素按照自然顺序或自定义比较器排序 |
| 时间复杂度 | O(1):理想情况下,基于哈希的直接定位 | O(log n):基于红黑树的查找、插入、删除 |
| null 值处理 | 允许一个 null key 和多个 null value | 不允许 null key(会抛 NullPointerException),但允许 null value(需注意比较器处理) |
| 实现接口 | 实现 Map 接口 | 实现 SortedMap 和 NavigableMap 接口 |
| 依赖方法 | 依赖 hashCode() 和 equals() 方法 | 依赖 Comparable 或 Comparator 接口 |
| 适用场景 | 插入、删除、查找操作频繁,不关心顺序 | 需要有序遍历(如范围查询、排序输出) |
| 性能特点 | 插入/删除/查找快(哈希直接定位) | 插入/删除/查找较慢(需维护树平衡),但有序遍历快 |
# 9、Collection和Collections的区别
Collection是单列集合的顶层接口,Map是双列集合的顶层接口
Collections是一个集合的工具类,提供了排序、查找等操作集合的一些常用方法。
# 10、 Collection框架中实现比较要怎么做?
第一种,实体类实现Comparable<T>接口,并实现 compareTo(T t) 方法,我们称为内部比较器。
第二种,创建一个外部比较器,这个外部比较器要实现Comparator接口的 compare(T t1, T t2)方法。
comparable 和 comparator的区别:
- comparable接口实际上是出自java.lang包,它有一个 compareTo(Object obj)方法用来排序
- comparator接口实际上是出自 java.util 包,它有一个compare(Object obj1, Object obj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo方法或compare方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌手名排序,第二种代表我们只能使用两个参数版的Collections.sort().
例子:
public class ComparatorTest {
public static void main(String[] args) {
Student xiaoming = new Student("xiaoming", 20);
Student xiaohong = new Student("xiaohong", 21);
Student xiaogang = new Student("xiaogang", 19);
List<Student> list = new ArrayList<Student>();
list.add(xiaohong);
list.add(xiaoming);
list.add(xiaogang);
//因为Student类已经重写了compareTo方法
System.out.println("已重写后的list --->>>" + list);
//自定义排序
Collections.sort(list, new Comparator<Student>() {
@Override
//升序
public int compare(Student o1, Student o2) {
return o1.getAge().compareTo(o2.getAge());
}
});
//自定义排序
System.out.println("自定义排序list --->>>" + list);
}
}
class ComparatorTest2 implements Comparator<Student> {
public static void main(String[] args) {
Student xiaoming = new Student("xiaoming", 20);
Student xiaohong = new Student("xiaohong", 21);
Student xiaogang = new Student("xiaogang", 19);
List<Student> list = new ArrayList<>();
list.add(xiaohong);
list.add(xiaoming);
list.add(xiaogang);
System.out.println("已重写后的list --->>>" + list);
ComparatorTest2 comparatorTest = new ComparatorTest2();
System.out.println("自定义比较--->>>"+comparatorTest.compare(xiaoming, xiaohong));
}
//重写compare方法,用于单独比较
@Override
public int compare(Student o1, Student o2) {
return o1.getAge().compareTo(o2.getAge());
}
}
@Data
class Student implements Comparable<Student> {
String name;
Integer age;
Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Student o2) {
//降序
return this.getAge().compareTo(o2.getAge());
}
}
第一个main输出:
已重写后的list --->>>[Student(name=xiaohong, age=21), Student(name=xiaoming, age=20), Student(name=xiaogang, age=19)]
自定义排序list --->>>[Student(name=xiaogang, age=19), Student(name=xiaoming, age=20), Student(name=xiaohong, age=21)]
第二个main输出:
已重写后的list --->>>[Student(name=xiaohong, age=21), Student(name=xiaoming, age=20), Student(name=xiaogang, age=19)]
自定义比较--->>>-1
# 11、ConcurrentHashMap分段锁
jdk1.7中:
ConcurrentHashMap 是由 Segment 数组结构 + HashEntry 数组结构 + 链表 组成。Segment 是一种可重入锁 ReentrantLock,在 ConcurrentHashMap 里扮演锁的角色,HashEntry 则用于存储键值对数据。
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
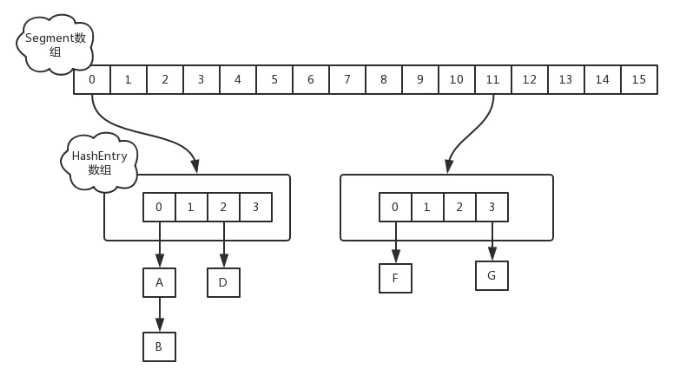
jdk1.8中:
放弃了Segment,直接用 Node数组+链表+红黑树 的数据结构来实现,并发控制使用Synchronized + CAS来操作,整个看起来就像是优化过且线程安全的HashMap。
# 12、遍历一个 List 有哪些不同的方式?
- for 循环遍历,基于计数器。在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后停止。
- 迭代器遍历,Iterator。Iterator 是面向对象的一个设计模式,目的是屏蔽不同数据集合的特点,统一遍历集合的接口。Java 在 Collections 中支持了 Iterator 模式。
- foreach 循环遍历。foreach 内部也是采用了 Iterator 的方式实现,使用时不需要显式声明 Iterator 或计数器。优点是代码简洁,不易出错;缺点是只能做简单的遍历,不能在遍历过程中操作数据集合,例如删除、替换。
System.out.println("-----------forEach遍历-------------");
list.parallelStream().forEach(k -> {
System.out.println(k);
});
System.out.println("-----------for遍历-------------");
for (Student student : list) {
System.out.println(student);
}
System.out.println("-----------Iterator遍历-------------");
Iterator<Student> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
# 13、如何实现数组和 List 之间的转换?
- 数组转 List:使用 Arrays. asList(array) 进行转换。
- List 转数组:使用 List 自带的 toArray() 方法。
// list to array
List<String> list = new ArrayList<String>();
list.add("HaC");
list.add("HelloCoder");
Object[] str = list.toArray();
// array to list
String[] array = new String[]{"HaC", "HelloCoder"};
List<String> mylist = Arrays.asList(array);
# 14、hashCode()与equals()
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个equals方法返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的(哈希冲突)
- 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
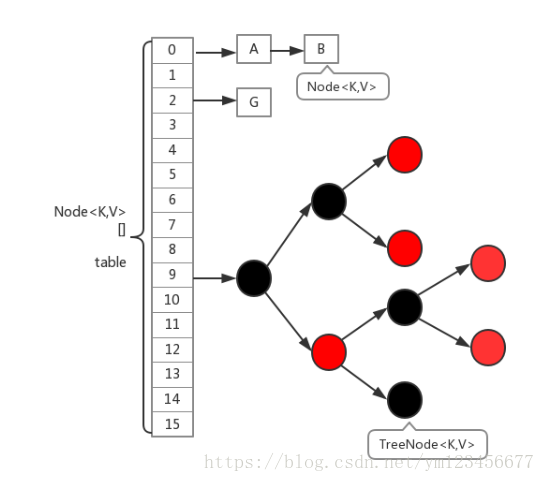
# 15、HashMap原理、哈希冲突的解决
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞、哈希冲突)
为什么1.8中引入红黑树?
当我们的HashMap中存在大量数据时,加入我们某个bucket下对应的链表有n个元素,那么遍历时间复杂度就为O(n),为了针对这个问题,JDK1.8在HashMap中新增了红黑树的数据结构,进一步使得遍历复杂度降低至O(logn);
JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间
简单总结一下HashMap是使用了哪些方法来有效解决哈希冲突的:
使用链地址法(使用散列表)来链接拥有相同hash值的数据;
使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;
引入红黑树进一步降低遍历的时间复杂度,使得遍历更快;
HashMap什么时候进行扩容?
当HashMap中的元素个数超过数组大小 * loadFactor 时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16 * 0.75=12的时候,就把数组的大小扩展为2 * 16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设数组的大小能够有效的提高HashMap的性能。
比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面已经说过,即使是1000,HashMap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1024 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,避免了resize的问题。
可以这样说:
1.添加元素的时候会检查容器当前元素个数。当HashMap的容量值超过了临界值(默认16 * 0.75=12)时扩容。
2.HashMap将会重新扩容到下一个2的指数幂(16->32->64)。
3.调用resize方法,定义长度为新长度(32)的数组,然后对原数组数据进行再Hash。这个过程是一个性能损耗点。
