 HashMap的put过程是怎么样的?
HashMap的put过程是怎么样的?
HashMap的问题,能扯几个小时,而且还是挺刁钻的, 所以还是很有必要看一下HashMap实现的源码。
不仅要所以然,还要之所以然。
# 1、HashMap
HashMap作为集合的一员大将,它是非线程安全,以key、value(键值)对格式存储。
# 2、HashMap的底层结构是什么?
在JDK1.7和JDK1.8中,两个不同版本的HashMap有差异。
1.7中:数组+链表
1.8中:数组+链表或红黑树
HashMap图示如下所示:
(借用一张图,左侧是链表的,右侧是红黑树的,这两者的查询效率红黑树要高)
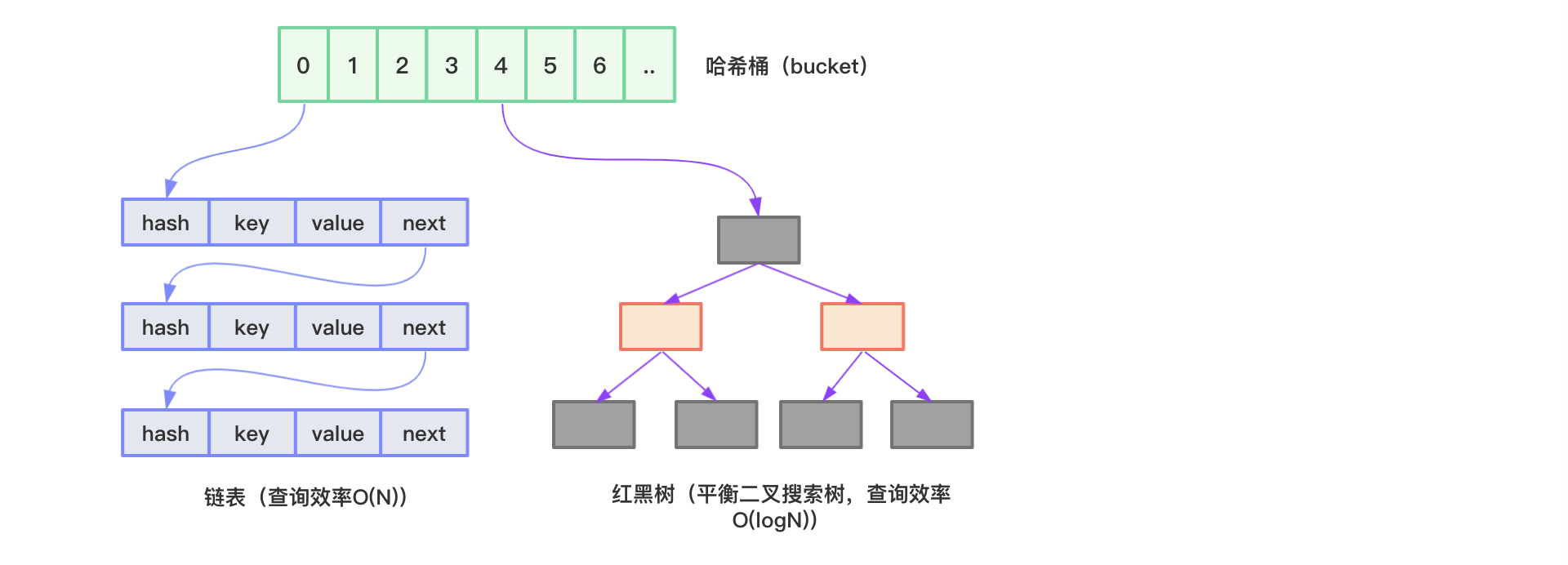
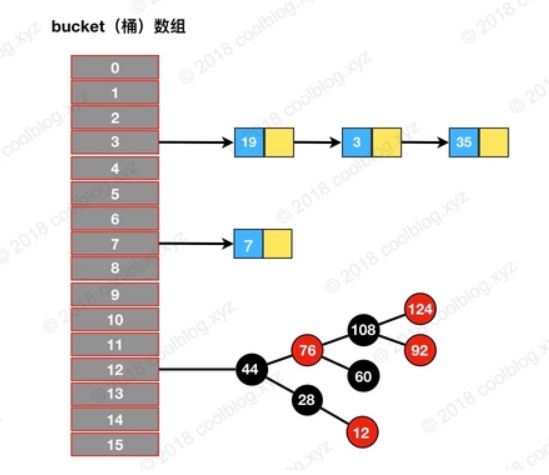
数组优点:通过数组下标可以快速实现对数组元素的访问,效率极高;
链表优点:插入或删除数据不需要移动元素,只需修改节点引用,效率极高。
红黑树优点:大大减少了查找时间,以加快检索速度
# 2、HashMap之put过程
这里以jdk1.8进行分析
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
然后再调用自己的hash() 方法把key取hash值:
static final int hash(Object key) {
int h;
//hashCode是父类的Object方法
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个过程中:如果key为null那么就将键值取0,如果不为空则计算key的hashcode值,将h右移16位进行异或运算得到hash值。
# 2.1、为什么要异或运算?为什么要右移16位?
首先采用位运算符会十分快。>>>无符号右移,低位挤走,高位补0;^ 为按位异或,即转成二进制后,相异为 1,相同为 0
& 运算符,两个操作数中位都为1,结果才为1,否则结果为0,所以结果向 0 靠拢。
| 运算符,两个操作数中有一个为1,结果就为1,否则为0,所以结果会向 1 靠拢。
采用 异或, 而且是16位,是因为hash后是int类型,32位,高位、低位各16位对半,而异或又可以让 0、1 均匀(不像&、| 靠拢),所以得出的hash值会更均匀,也就避免了hash冲突。
最终目的还是为了让哈希后的结果更均匀的分布,减少哈希碰撞,提升hashmap的运行效率
接着看put的核心源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果数组(哈希表)为null或者长度为0,则进行数组初始化操作,这里就是扩容操作 默认是 1<<4=16的容量
// 扩容阈值为 1<<4 * 0.75 = 12 ,就是说容量大于12时,数组就会扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//这个是key的数据插入数组的下标位置算法,(n - 1) & hash 这样下标肯定就是在 n 之内了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//hash冲突部分
else {
Node<K,V> e; K k;
// 如果目标位置key已经存在,则直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果已经是红黑树结构了,就插入红黑树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果是链表,则遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表长度大于等于 TREEIFY_THRESHOLD=8,则考虑转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//这里面还有判断
treeifyBin(tab, hash);
break;
}
// 这里会判断hash的值 是否存在
// 如果链表中已经存在该key的话,直接覆盖替换
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
//被替换的旧值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 当键值对个数大于等于扩容阈值的时候,进行扩容操作
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
put操作过程总结:(重要)
判断HashMap数组是否为空,是的话初始化数组(由此可见,在创建HashMap对象的时候并不会直接初始化数组);
通过
(n-1) & hash计算key在数组中的存放索引;如果此时table的对应位置没有任何元素,也就是table[i]=null,那么就直接把Node放入table[i]的位置,并且这个Node的
next==null,并且返回 null目标索引位置不为空的话,分下面三种情况:
4.1. (相同hash值,还会调用equals方法比较内容是否相同),都相同则覆盖旧值;
4.2. 该节点类型是红黑树的话,执行红黑树插入操作,根据hash值向红黑树中添加或替换TreeNode。(JDK1.8)
4.3. 该节点类型是链表的话,遍历到最后一个元素尾插入,则把新的Node插入链表的末端,作为之前末端Node的next,同时新Node的next==null,返回null
如果期间有遇到key相同的,则直接覆盖。
如果链表长度大于等于
TREEIFY_THRESHOLD=8,并且数组容量大于等于MIN_TREEIFY_CAPACITY = 64,则将链表转换为红黑树结构;
判断HashMap元素个数是否大于等于threshold(
16*0.75),是的话,进行扩容操作。
# 3、为什么是红黑树?
红黑树:是许多二叉查找树中的一种,它能保证在最坏的情况下,基本动态集合操作时间为O(lgn)。
上面提到的链表,是为了解决Hash碰撞、冲突,产生冲突的那些KEY对应的记录只是简单的追加到一个链表后面,这些记录只能通过遍历来进行查找。
在链表中查找数据必须从第一个元素开始一层一层往下找,如果hash冲突多,那么查询的效率就越低,接近O(N)
所以引入了红黑树,数据查询时间复杂度为O(logN)。
# 4、为什么不直接采用红黑树还要用链表?
因为红黑树需要进行左旋,右旋操作, 而单链表不需要,如果元素小于8个,查询成本高,新增成本低;如果元素大于8个,查询成本低,新增成本高。
红黑树(Red Black Tree) 是一种自平衡二叉查找树
红黑树的插入过程比较复杂,它会通过自旋达到平衡,如果元素较多,效率会十分低,我下面演示一下:
我依次插入 10,20,30,15 到一个空树中:
https://www.cs.usfca.edu/~galles/visualization/RedBlack.html (opens new window)
# 5、1.8和1.7的区别
JDK1.7 hash计算规则为:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
如果是字符串计算,性能要差一点。
另外就是put方法,jdk1.7没有用到红黑树,只能通过链表解决,在HashMap扩容时,会改变链表中的元素的顺序,将元素从链表头部插入。
如果在线程竞争下进行同时扩容,就有可能形成闭环,参考:https://blog.csdn.net/hhx0626/article/details/54024222
# 6、一些细节和 参数
# 6.1、什么时候转换成红黑树?
上面代码看到如果链表长度超过 8 调用treeifyBin()方法转换红黑树,但是再看看treeifyBin()方法:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) //MIN_TREEIFY_CAPACITY = 64
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
可以看到,如果数组(桶)的长度 小于 64,走的是扩容,而不是转化为数。
所以转换成红黑树的条件是:
- 链表长度超过 8
- 数组(桶)的长度超过 64
# 6.2、初始化容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4
初始容量,默认容量=16,箱子的个数不能太多或太少。如果太少,很容易触发扩容,如果太多,遍历哈希表会比较慢。
# 6.3 负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f
当存储的所有节点数 大于 (16 * 0.75 = 12 )时,就会触发扩容,这个是泊松分布?折中的方法减少rehash次数,提高查找成本。
修改容量的方法是这样的:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
所以要注意,如果要往HashMap中放1000个元素,又不想让HashMap不停的扩容,最好一开始就把容量设为2048,设为1024不行,因为元素添加到七百多的时候还是会扩容。
# 6.4、什么时候退化为链表?
static final int UNTREEIFY_THRESHOLD = 6
在哈希表扩容时,如果发现链表长度 <= 6,则会由树重新退化为链表。
为什么要设置为6? 可能是因为时间和空间的权衡
因为链表的查询时间复杂度是 O(n),红黑树是O(logn)
当链表长度为6时 查询的平均长度为 n/2=3(大部分情况不会在最后位置的~),红黑树 log(6) = 2.6 ,为8时 :链表 8/2=4, 红黑树 log(8)=3。
所以在小于6的时候,链表查询会快一点,空间也节省一点。
参考:
- https://www.jianshu.com/p/104fa73c81b3 这个讲红黑树强的一批
- https://mrbird.cc/Java-HashMap%E5%BA%95%E5%B1%82%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86.html
- https://blog.csdn.net/lkforce/article/details/89521318 可以看看这个,这个有画图看的更明白
