 10个实用的Linux技巧
10个实用的Linux技巧
# 1、查找当前目录下所有以.gz结尾的文件
查找当前目录超过30天没有修改过且文件大于10M的.gz文件。
find . -name "*.gz" -type f -ctime +30 -size +10M -exec ls -l {} \;
find . 表示当前目录及其子目录下
find /表示根目录及其子目录下
-name 表示文件名称,-name "*.gz" 表示不以*.gz 结尾的文件
-type 文件类型
d: 目录
c: 字型装置文件
b: 区块装置文件
p: 具名贮列
f: 一般文件
-ctime +表示更改时间
-atime -n[+n]: 找出文件访问时间在n日之内[之外]的文件。
-ctime -n[+n]: 找出文件更改时间在n日之内[之外]的文件。
-mtime -n[+n]: 找出修改数据时间在n日之内[之外]的文件。
-amin -n[+n]: 找出文件访问时间在n分钟之内[之外]的文件。
-cmin -n[+n]: 找出文件更改时间在n分钟之内[之外]的文件。
-mmin -n[+n]: 找出修改数据时间在n分钟之内[之外]的文件。
-size :表示大小,+表示超过指定大小的文件,-反之。
-exec 、xargs:查找后再执行操作
{} \; {}表示结果,\ 表示操作的目录
将software目录下大于100k的文件移动至/tmp下:
find /software -size +100k -exec mv {} /tmp ;
# 2、统计Nginx的访问IP次数
先找到你的Nginx日志:
[root@VM-8-8-centos ~]# find / -name 'access.log'
/usr/local/nginx/logs/access.log
[root@VM-8-8-centos ~]# cd /usr/local/nginx/logs/
[root@VM-8-8-centos logs]#
然后统计
cat access.log |awk '{print $1}'|sort|uniq -c |sort -nr |head -5
# 3、一键获取内存、CPU、磁盘、IO 等信息
#!/bin/bash
# 获取要监控的本地服务器IP地址
IP=`ifconfig | grep inet | grep -vE 'inet6|127.0.0.1' | awk '{print $2}'`
echo "IP地址:"$IP
# 获取cpu总核数
cpu_num=`grep -c "model name" /proc/cpuinfo`
echo "cpu总核数:"$cpu_num
# 1、获取CPU利用率
################################################
#us 用户空间占用CPU百分比
#sy 内核空间占用CPU百分比
#ni 用户进程空间内改变过优先级的进程占用CPU百分比
#id 空闲CPU百分比
#wa 等待输入输出的CPU时间百分比
#hi 硬件中断
#si 软件中断
#################################################
# 获取用户空间占用CPU百分比
cpu_user=`top -b -n 1 | grep Cpu | awk '{print $2}' | cut -f 1 -d "%"`
echo "用户空间占用CPU百分比:"$cpu_user
# 获取内核空间占用CPU百分比
cpu_system=`top -b -n 1 | grep Cpu | awk '{print $4}' | cut -f 1 -d "%"`
echo "内核空间占用CPU百分比:"$cpu_system
# 获取空闲CPU百分比
cpu_idle=`top -b -n 1 | grep Cpu | awk '{print $8}' | cut -f 1 -d "%"`
echo "空闲CPU百分比:"$cpu_idle
# 获取等待输入输出占CPU百分比
cpu_iowait=`top -b -n 1 | grep Cpu | awk '{print $10}' | cut -f 1 -d "%"`
echo "等待输入输出占CPU百分比:"$cpu_iowait
#2、获取CPU上下文切换和中断次数
# 获取CPU中断次数
cpu_interrupt=`vmstat -n 1 1 | sed -n 3p | awk '{print $11}'`
echo "CPU中断次数:"$cpu_interrupt
# 获取CPU上下文切换次数
cpu_context_switch=`vmstat -n 1 1 | sed -n 3p | awk '{print $12}'`
echo "CPU上下文切换次数:"$cpu_context_switch
#3、获取CPU负载信息
# 获取CPU15分钟前到现在的负载平均值
cpu_load_15min=`uptime | awk '{print $11}' | cut -f 1 -d ','`
echo "CPU 15分钟前到现在的负载平均值:"$cpu_load_15min
# 获取CPU5分钟前到现在的负载平均值
cpu_load_5min=`uptime | awk '{print $10}' | cut -f 1 -d ','`
echo "CPU 5分钟前到现在的负载平均值:"$cpu_load_5min
# 获取CPU1分钟前到现在的负载平均值
cpu_load_1min=`uptime | awk '{print $9}' | cut -f 1 -d ','`
echo "CPU 1分钟前到现在的负载平均值:"$cpu_load_1min
# 获取任务队列(就绪状态等待的进程数)
cpu_task_length=`vmstat -n 1 1 | sed -n 3p | awk '{print $1}'`
echo "CPU任务队列长度:"$cpu_task_length
#4、获取内存信息
# 获取物理内存总量
mem_total=`free | grep Mem | awk '{print $2}'`
echo "物理内存总量:"$mem_total
# 获取操作系统已使用内存总量
mem_sys_used=`free | grep Mem | awk '{print $3}'`
echo "已使用内存总量(操作系统):"$mem_sys_used
# 获取操作系统未使用内存总量
mem_sys_free=`free | grep Mem | awk '{print $4}'`
echo "剩余内存总量(操作系统):"$mem_sys_free
# 获取应用程序已使用的内存总量
mem_user_used=`free | sed -n 3p | awk '{print $3}'`
echo "已使用内存总量(应用程序):"$mem_user_used
# 获取应用程序未使用内存总量
mem_user_free=`free | sed -n 3p | awk '{print $4}'`
echo "剩余内存总量(应用程序):"$mem_user_free
# 获取交换分区总大小
mem_swap_total=`free | grep Swap | awk '{print $2}'`
echo "交换分区总大小:"$mem_swap_total
# 获取已使用交换分区大小
mem_swap_used=`free | grep Swap | awk '{print $3}'`
echo "已使用交换分区大小:"$mem_swap_used
# 获取剩余交换分区大小
mem_swap_free=`free | grep Swap | awk '{print $4}'`
echo "剩余交换分区大小:"$mem_swap_free
#5、获取磁盘I/O统计信息
echo "指定设备(/dev/sda)的统计信息"
# 每秒向设备发起的读请求次数
disk_sda_rs=`iostat -kx | grep sda| awk '{print $4}'`
echo "每秒向设备发起的读请求次数:"$disk_sda_rs
# 每秒向设备发起的写请求次数
disk_sda_ws=`iostat -kx | grep sda| awk '{print $5}'`
echo "每秒向设备发起的写请求次数:"$disk_sda_ws
# 向设备发起的I/O请求队列长度平均值
disk_sda_avgqu_sz=`iostat -kx | grep sda| awk '{print $9}'`
echo "向设备发起的I/O请求队列长度平均值"$disk_sda_avgqu_sz
# 每次向设备发起的I/O请求平均时间
disk_sda_await=`iostat -kx | grep sda| awk '{print $10}'`
echo "每次向设备发起的I/O请求平均时间:"$disk_sda_await
# 向设备发起的I/O服务时间均值
disk_sda_svctm=`iostat -kx | grep sda| awk '{print $11}'`
echo "向设备发起的I/O服务时间均值:"$disk_sda_svctm
# 向设备发起I/O请求的CPU时间百分占比
disk_sda_util=`iostat -kx | grep sda| awk '{print $12}'`
echo "向设备发起I/O请求的CPU时间百分占比:"$disk_sda_util
注意:部分命令不适合Ubuntu,不同的centos版本也有区别。
参考:https://www.toutiao.com/i6754887380399849998/
部分命令介绍:
vmstat -n 1 1只显示一次各字段名称。
ed -n 3p将第一步的结果打印出第3行
参数说明:
-n或--quiet或--silent 取消自动打印模式空间,仅显示script处理后的结果。
动作说明:
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
cut -f 1 -d "%" 表示以%为分隔符,将第三步的结果分隔开,并显示分割后的记过的第一个字符串即0.5
-d "%" 是以%作为分隔符,
-f 1 显示以:分割每一行的第一段内容
# 4、快速生成大文件
dd if=/dev/zero of=file bs=1M count=1000
会生成一个10G的file 文件,文件内容为全0(因从/dev/zero中读取,/dev/zero为0源)。
如果只想产生一个大文件的数据,但是并不需要占用磁盘空间,则可以使用如下命令:
dd if=/dev/zero of=file bs=1M count=0 seek=20000
# 5、快速清空文件
我常用的是
> access.log
以下也都可以:
: > access.log
: 在 shell 中是一个内置命令,表示 no-op,大概就是空语句的意思
true > access.log
cat /dev/null > access.log
echo -n "" > access.log
echo > access.log
truncate -s 0 access.log
# 6、动态查看日志,并且停止
如果想在日志中出现 Exception 等信息时立刻停止 tail 监控,可以通过如下命令来实现:
tail -f test.log | sed '/Exception / q'
# 7、时间戳快速转换
date命令打印的时间是难以读懂的。
[root@localhost ~]# date
Wed Apr 14 16:58:17 CST 2021
[root@localhost ~]# date +%s
1618390650
我们可以使用 -d 来格式化:
[root@localhost ~]# date -d@1618390650 +"%Y-%m-%d %H:%M:%S"
2021-04-14 16:57:30
[root@localhost ~]# date +"%Y-%m-%d %H:%M:%S"
2021-04-14 17:00:29
# 8、获取公网ip
ifconfig、ip addr 命令只能获取到当前网卡的局域网IP,但是如果你想获取你的公网IP,可以试一下:
curl ip.sb
# 9、通过curl计算下载文件的时间
curl -L -H "User-Agent: mz-lastmile" --connect-timeout 10 --max-time 15 -o /dev/null -s -w response_code:"\t\t"%{response_code}"\n"content_type:"\t\t"%{content_type}"\n"time_namelookup:"\t"%{time_namelookup}"\n"time_redirect:"\t\t"%{time_redirect}"\n"num_redirects:"\t\t"%{num_redirects}"\n"time_connect:"\t\t"%{time_connect}"\n"time_appconnect:"\t"%{time_appconnect}"\n"time_pretransfer:"\t"%{time_pretransfer}"\n"time_starttransfer:"\t"%{time_starttransfer}"\n"time_total:"\t\t"%{time_total}"\n"size_header:"\t\t"%{size_header}"\n"size_download:"\t\t"%{size_download}"\n"speed_download:"\t\t"%{speed_download}"\n" https://cdn.jsdelivr.net/gh/DogerRain/image@main/Home/HelloCoder.png
-L 表示使用重定向,找到最终都URL -H 表示使用header -s -w 表示 使用参数 -o /dev/null 表示写到null文件 --connect-timeout 表示连接超时时间 --max-time 表示 最长等待时间(下载时间,包括连接超时时间,是总的时间)
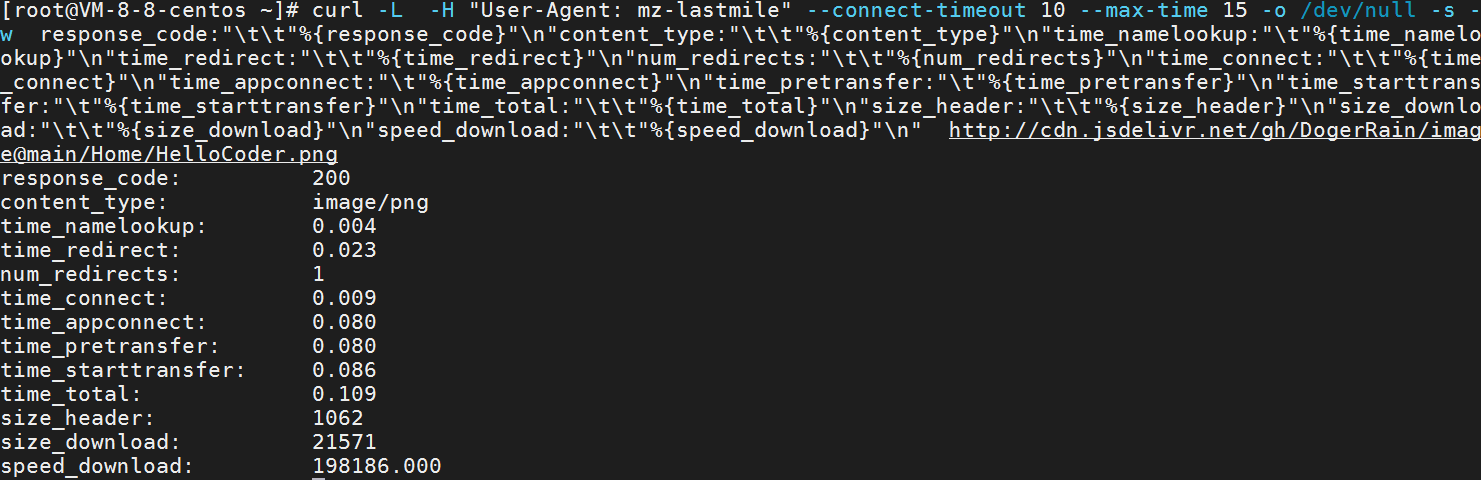
含义:
response_code 返回码,200表示成功
time_namelookup DNS解析时间,从请求开始到DNS解析完毕所用时间(记得关掉 Linux 的 nscd 的服务测试)
content_type 文件类型
time_redirect 重定向花费的时间
num_redirects 重定向次数,0表示没有重定向,则time_redirect 也是0
time_connect 建立到服务器的 TCP 连接所用的时间 (包含了DNS时间,如果要求 纯TCP建立时间,应该是time_connect-time_namelookup) 出发前所有准备的时间
time_appconnect 从发出请求到服务器耗时(即建立TCP+SSL耗时,纯ssl握手耗时:time_appconnect -time_connect) 出发+到达服务器的所有时间
time_starttransfer 在发出请求之后,Web 服务器返回数据的第一个字节所用的时间(time_starttransfer -time_appconnect 阔以理解为服务器发包到客户端需要的时间)三次握手的耗时
time_total 完成请求所用的时间
size_header 表头大小
size_download 下载文件总大小
speed_download 下载速度,单位-字节每秒。
我最喜欢用来统计一个接口的耗时,结合ping命令结算延迟和丢包率,就可以做CDN判断了。
# 10、历史命令使用技巧
- !!:重复执行上条命令;
- !N:重复执行 history 历史中第 N 条命令,N 可以通过 history 查看;
- !pw:重复执行最近一次,以pw开头的历史命令,这个非常有用,小编使用非常高频;
- !$:表示最近一次命令的最后一个参数;
猜测大部分同学没用过 !$,这里简单举个例子,让你感受一下它的高效用法
$ vim /root/sniffer/src/main.c
$ mv !$ !$.bak
# 相当于
$ mv /root/sniffer/src/main.c /root/sniffer/src/main.c.bak
当前工作目录是 root,想把 main.c 改为 main.c.bak。正常情况你可能需要敲 2 遍包含 main.c 的长参数,当然你也可能会选择直接复制粘贴。
而我通过使用 !$ 变量,可以很轻松优雅的实现改名。
但是!
在所要执行的命令前,加一个空格,那这条命令就不会被 history 保存到历史记录。
有时候,执行的命令中包含敏感信息,这个小技巧就显得非常实用了,你也不会再因为忘记执行 history -c 而烦恼了。
