 高并发系统的设计
高并发系统的设计
高并发总会出现各种各样的问题,带来的就是各种各样的技术解决方案。
但是目前大多公司都是面向业务开发,有过相关经历的小伙伴就知道了,无非就是简单的调接口。
所以并不是每个程序员都能切身体会到高并发的场景,更多的是停留在理论上面。
我现在说的也是理论~
可能面试官也不一定接触过高并发业务。而在面试中,偏偏喜欢问你的项目有多少流量、有没有高并发、以及高并发解决方案。
先说两个坑吧:
第一是直接回答没有高并发经验。
这种没有经验,但我相信你可以尝试去回答,有无经验不影响你做出你的看法,你可以尝试这样说:
1、公司的业务简单,没有接触过,但我可以谈谈我的思路
第二是直接说加机器,升级设备。
如果你真的没接触过高并发,而且没有理论知识(毕竟大部分公司都没有高并发的业务,不是为了面试谁会看这个),你可以用jmeter压测试一下,开个10w的请求去测试自己的服务,如何保证业务的一致性、如何负载均衡、如何响应,最后查看一下jmeter的response,并尝试去优化。
# 1、对高并发的理解
常见的高并发场景:12306抢票、吃瓜事件微博宕机、淘宝双十一。
什么样的流量才算是高并发呢?
技术围绕着业务。高并发不能只看QPS、TPS、吞吐量,因为不同的业务场景不一样,执行复杂度也不一样,单看并发量没有意义。
我所理解的高并发是机器在有限的资源内承受最大的压力。
遇到高并发并不是加机器,而是从系统设计、代码、甚至是业务场景中下手。
那如何衡量一个系统是否扛得住高并发的流量呢?
通常衡量一个Web系统的吞吐率的指标是QPS(Query Per Second,每秒处理请求数)
举个例子,我们假设处理一个业务请求平均响应时间为100ms,同时,系统内有20台Apache的Web服务器,配置MaxClients为500个(表示Apache的最大连接数目)。
那么,我们的Web系统的理论峰值QPS为(理想化的计算方式):
20*500/0.1 = 100000 (10万QPS)
咦?我们的系统似乎很强大,1秒钟可以处理完10万的请求,5w/s的秒杀似乎是“纸老虎”哈。实际情况,当然没有这么理想。在高并发的实际场景下,机器都处于高负载的状态,在这个时候平均响应时间会被大大增加。
另外,从用户体验角度来看,200毫秒被认为是第一个分界点,用户感觉不到延迟,1秒是第二个分界点,用户能感受到延迟,但是可以接受。
# 2、高并发的解决方案
# 1、scale-up 纵向扩展
scale-up 纵向扩展,基本上是从硬件层面出发,常见的是:
1、通过增加内存、CPU核数、升级磁盘、带宽等堆硬件的方式来提升。
2、其次是服务器的性能,比如缓存减少IO次数、Linux网络内核调优等。
# 2、scale-out 横向扩展
上面说到升级机器的硬件,但这是在单机层面考虑的。
单机的性能存在极限,这时候多机集群就是很好的解决方案了,但复杂度也随之增加。
虽然加了机器,做了集群,但还是要做好每一台机器的分层。
现在的解决套路无非就是:
前端优化—>系统拆分—>负载均衡—>缓存—>异步—>分库
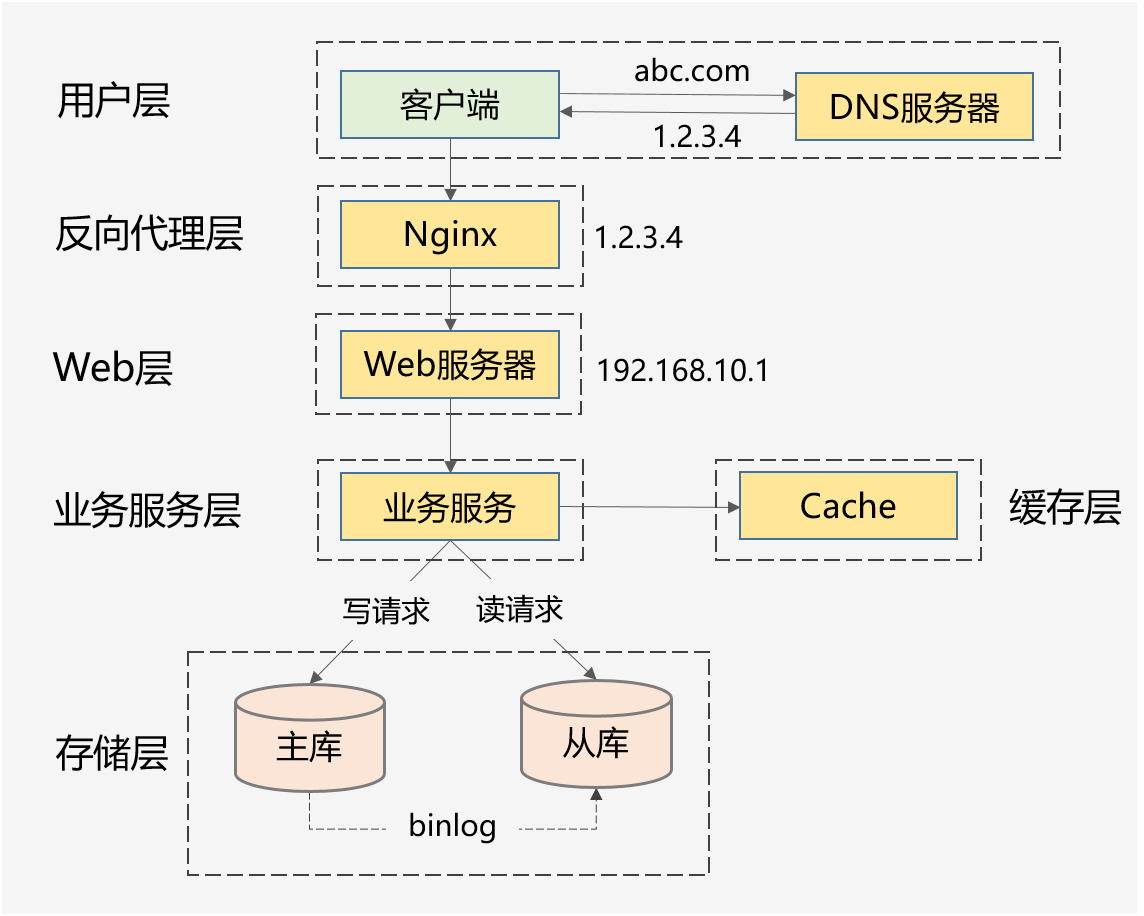
(图片转自《武哥漫谈IT》)
下面是简单的实践:
# 纵向层面:
# 1、堆机器
1台8核8G的服务器很可能干不过4台2核2G的机器。 而且1台1万块钱的机器也干不过10台1千块钱的机器。
# 2、机器调优
JVM
JVM层面也有,比如说堆内存分配空间大小,堆内存不足,线程创建失败,频繁GC,影响业务。
CPU、内存
CPU占用率、内存占用率,可以使用free、top 观察一下。
还有Linux调优的参数诸如:
限制并发连接的最大数量fs.file-max、端口状态保留时间TIME_WAIT、每个套接字允许的最大辅助缓冲区大小net.core.optmem_max、Socket接收/发送缓存最大值net.core.rmem_max
TIME_WAIT状态保留一定的时间,当并发请求过多的时候,就会产生大量的TIME_WAIT状态的连接,无法及时断开的话,会占用大量的端口资源和服务器资源。
可以使用以下命令看一下TIME_WAIT端口:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
还有一些常用的优化:
# 指示进程(例如工作进程)可同时打开的最大句柄数,直接限制并发连接的最大数量。
# 默认值:fs.file-max = 141079
fs.file-max = 655350
# 启用keepalive时,TCP发送keepalive消息的频率。默认值为2小时。将其调低一点以更快地删除无用的连接
# 默认值:net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_time = 1200
# 当服务器主动关闭链接时,套接字保持FN-WAIT-2状态的最大时间
# 默认值:net.ipv4.tcp_fin_timeout = 60
net.ipv4.tcp_fin_timeout = 30
# 该参数决定了,网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
# 默认值:net.core.netdev_max_backlog = 1000
net.core.netdev_max_backlog = 8192
# 每个套接字允许的最大辅助缓冲区大小。辅助数据是带有附加数据的结构cmsghdr结构的序列。
# 默认值:net.core.optmem_max = 20480
net.core.optmem_max = 81920
# 指定了接收套接字缓冲区大小的最大值(以字节为单位)。
# 默认值:net.core.rmem_default = 212992
net.core.rmem_default = 262144
# 允许最大数量的TIME-WAIT套接字。超过几位数,TIME-WAIT套接字将立即清除,并显示警告消息。默认值为8192,太多的TIME-WAIT套接字会减慢Web服务器的速度
# 默认值:net.ipv4.tcp_max_tw_buckets = 8192
net.ipv4.tcp_max_tw_buckets = 5000
# TCP接收/发送缓存最小值,默认值,最大值
# 默认值:net.ipv4.tcp_rmem = 4096 131072 6291456
net.ipv4.tcp_rmem = 4096 32768 262142
# 默认值:net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_wmem = 4096 32768 262142
# Socket接收/发送缓存最大值
# 默认值均为:212992
net.core.rmem_max = 4194304
net.core.wmem_max = 4194304
# 启用syncookies有助于防御dos攻击,会少量增加CPU使用率,默认启用
net.ipv4.tcp_syncookies = 1
# 接受SYN同步包的最大客户端数量,即半连接上限,128M内存情况下是缺省值1024
默认值:net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_max_syn_backlog = 8192
# 服务端所能accept即处理数据的最大客户端数量,即完成连接上限
默认值:net.core.somaxconn = 1024
net.core.somaxconn = 10240
# 横向层面:
# 1、前端优化
CDN加速
启用浏览器缓存和文件压缩、添加异步请求
禁止外部盗链
外部网站的图片或者文件盗链往往会带来大量的负载压力,因此应该严格限制外部对于自身的图片或者文件盗链。
# 2、系统拆分
系统拆分可以理解为分布式集群,假如目前有30个并发量,你单台机器最大的处理并发量是20,此时你可以加入另一台机器,理论上能处理的最大请求量就是40。
像目前的微服务springBoot、dubbo,其中还有一个重要的通信方式就是RPC调用,传统的服务通信都是HTTP的方式,多个服务之间使用RPC性能要好一点,而且可以进行链路追踪。
而且微服务还有Ribbon和Fegin这些负载均衡组件。
而在代码层面,可以假如接口超时机制、幂等性校验等等。
# 3、负载均衡:
还可以通过Nginx负载均衡,分发请求,让两个机器平均处理请求量。
Nginx负载均衡:内置策略:IP Hash,加权轮询;扩展策略:fair策略,通用hash,一致性hash
# 4、缓存
Redis、Memcache、布隆过滤器等等。
但要注意缓存穿透、击穿、雪崩。
还可以使用缓存预热,先把一部分的数据加载到缓存,不至于让数据库压力过大影响请求。
# 5、异步
引入MQ(还能解耦、削峰),把请求放到MQ,稍后处理,同步转异步。
# 6.数据库读写分离
分库分表,读写分离。
基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作,降低数据库的压力。
# 业务层面:
# 1、服务降级
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作,解决方案目前有流行的Spring Cloud Hystrix
比如说 直接返回“当前人数较多,请稍后重试”、限流处理、随机丢弃请求(好像淘宝的高并发业务就是这样的,要看业务),必要时进行熔断,触发失败rollback事件,随后慢慢进行数据核对。
# 2、数据核对
分布式系统需要考虑分布式事务,相比传统的单机服务,分布式事务的数据更难核对一致性,所以有必要建立数据核对平台。
# 监控层面:
这里说一下我们公司常见的监控手段:
# 1、监控报警
比如说链路追踪,跟踪调用链的时间和长度,快速追踪到哪个环节最耗时。
服务器CPU、内存、IO、网络,以及JVM、数据库(慢SQL)等等进行监控,在高并发请求业务下,快速定位。
# 2、灰度发布
模拟并发量。小流量部署,然后监控。
# 3、扩容
K8s可以动态扩容,在监测到服务压力激增的情况下,可以自动申请资源。
如果没有动态扩容机制,是否有备用机、灾备是否可以马上响应。
还有就是一个经验:二八原则:80%的高并发流量都在20%的时间产生。
以上。
