 聊聊MySQL索引的分类和结构吧
聊聊MySQL索引的分类和结构吧
# Q1:聊聊MySQL索引的分类和结构吧
MySQL的索引作为MySQL知识点的核心内容,几乎在面试的时候都会必问。
为什么面试官都喜欢问MySQL的索引呢?我觉得有以下理由:
- MySQL索引的设计十分高效,随着业务数据数量的激增诞生了B树、又过渡到了B+树。
- 只有对MySQL索引清晰地掌握,才能准确地给表加索引,才能在业务中优化SQL,定位问题。
索引是一种数据结构,索引本身很大,不可能全部存储在内存中,因此索引以索引表的形式存储在磁盘中。
这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
# Q2:MySQL索引的数据结构有哪几种
# 1、Hash索引
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
Hash 索引的查询效率要远高于 B-Tree 索引。
和Java的HashMap十分类似。
虽然 Hash 索引 效率高,但是也有局限性:
(1)不支持范围查询,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。所以它也不能用于排序
-- 哈希索引只适合等值查询
SELECT * FROM users WHERE id = 123; -- ✅ 哈希很快
SELECT * FROM users WHERE id > 100; -- ❌ 哈希无法支持范围查询
SELECT * FROM users WHERE name LIKE '张%'; -- ❌ 哈希无法支持前缀匹配
(2)不支持多列联合索引的最左匹配规则,对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(3)不能避免全表扫描;关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
所以这就是为什么不选哈希表。
# 2、B+树索引
说到B+树,就不得不提到B-树索引(B-树就是B树,中间的横线不是减号,所以不要读成B减树。)
# 2.1、B-树索引
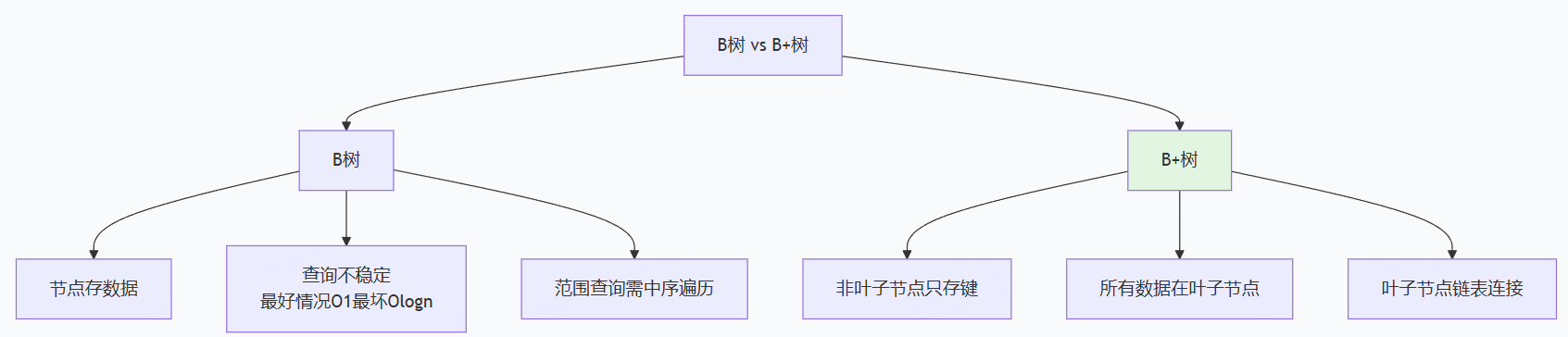
B树(Balance Tree)是一种多路平衡查找树,他的每一个节点最多包含M个孩子,M就是B树的阶。
M的大小取决于磁盘页的大小。

B树中无论中间节点还是叶子节点都带有卫星数据。
B+树中,只有叶子节点带卫星数据,其他中间节点仅仅是索引,没有数据关联。
# 2.2、B+树索引

根节点(非叶子)
[50]
/ \
/ \
中间节点(非叶子) 中间节点(非叶子)
[20, 40] [70, 90]
/ | \ / | \
/ | \ / | \
叶子节点 叶子节点 叶子节点 叶子节点 叶子节点
[10,15] [25,30] [45,48] [55,60] [75,80] [95,100]
↓ ↓ ↓ ↓ ↓ ↓
实际数据 实际数据 实际数据 实际数据 实际数据 实际数据
通过图片的对比,就能很清晰的区别B-树和B+树的区别。
B+树 每个叶子节点都带有指向下一个节点的指针,形成一个有序链表,中间节点没有卫星数据(存的不是整行的数据,而是指向下一层的索引),只有在最后一层叶子节点才存储实际数据;其他所有层都是非叶子节点(索引节点)。
两者的区别:
1、B+树中间节点没有卫星数据,所以同样大小的磁盘页上可以容纳更多节点元素。
这就意味着,数据量相同的情况下,B+树结构比B-树更加矮胖,因此查询时IO会更少。
2、B+树的查询必须最终找到叶子节点,而B-树只需要找到匹配的元素即可,无论匹配元素是中间节点还是叶子节点。
因此B-树的查找性能不稳定(最好情况是只查根节点,最坏查到叶子节点),而B+树每次查找都是稳定点 。
范围查询:
B-树只能依靠繁琐的中序遍历,而B+树只需要在链表上遍历即可。
综合起来,B+树比B-树优势有三个:
1、IO次数更少
2、查询性能稳定
3、范围查询简便。
以上是关于索引数据结构的回答,扩展问题还有:
