 消息队列面试题
消息队列面试题
# 1、消息队列是什么?为什么要使用消息队列?有什么优点?
消息队列简单的说,就是把消息放进一个先进先出的队列里面,生产者生产消息,消费者需要就进行消费。
- 把数据放到消息队列叫做生产者
- 从消息队列里取数据叫做消费者
优点:
解耦 未解耦前,有一天大佬叫我接入A系统,然后我就在代码里面调用了A,接下来大佬又叫我接入B、C系统,我又改了代码;忽然有一天,大佬说A系统不需要接入了,我又改了代码把它注释。
// 不需要调用A系统了,注释 // service.informA(message); service.informB(message); service.informC(message);如此反复,实在麻烦。
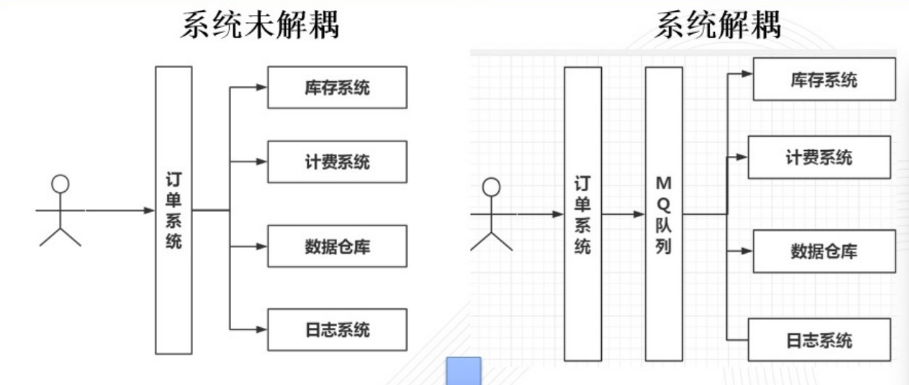
使用MQ,我就可以把消息交给mq去处理了,不用每次都要改我的代码了。
异步 假如A、B、C三个系统各需要50ms,这种调用方式就是串行的,加起来就是150ms;我使用mq,我只管把消息放在mq,然后直接返回,可能只需要100ms。
削峰(限流)
假如系统请求量非常大, 5k/s 的请求,我的两台服务器每台分别只能处理2k/s的请求,多出来的1k/s的请求可能就会把我的服务器搞崩溃。
如果我用了mq,就把5k的请求都收到mq队列里面,两台服务器处理完了再去取。
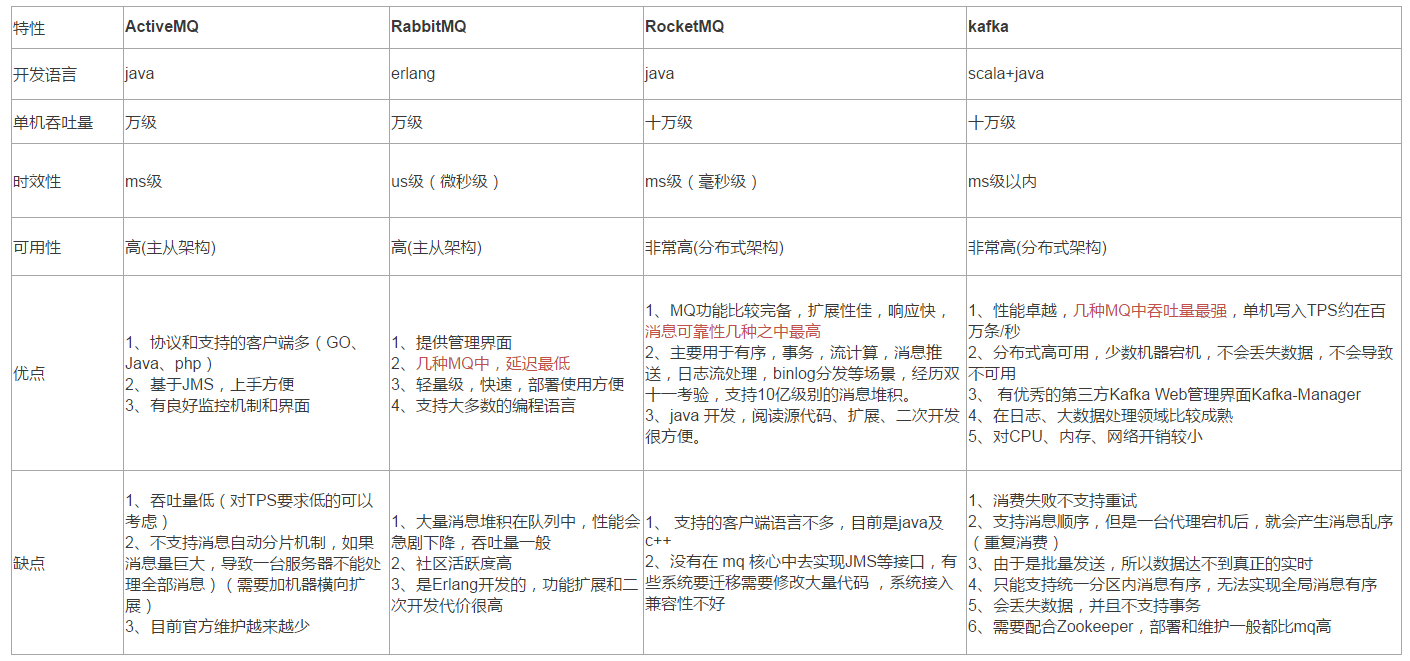
# 2、常见的消息队列,有什么区别?
# 3、使用mq会有哪些问题呢,怎么解决?
1)高可用问题
上面提到的例子,假如我的mq队列挂了,那就没办法接收消息了。我的A、B、C系统就不能用了。 解决:保证mq高可用,可以使用集群的方式。
RabbitMQ就可以部署集群方式,虽然也有单机模式,但是生产单机模式风险大。
而Kafka天生就是一个分布式的消息队列。
以rcoketMQ为例,他的集群就有多master 模式、多master多slave异步复制模式
2)系统开发复杂度提升,既然是交给了mq处理,如何处理重复消费、消息丢失的问题的呢。
3)消息一致性的问题,mq把消息发给多给系统,怎么确定这个消息是被所有的系统消费了呢?
2、3 这两点,也是经常被问到的,下面详细说。
# 4、消息如何保证幂等性(重复消费问题)
首先RabbitMQ、RocketMQ、Kafka都有可能会出现消息重复消费的问题,这也是正常的。因为这问题通常不是 MQ 自己保证的,比如说宕机、重启;这是由我们开发来保证的。
以Kafka来说,kafka有一个offset的操作,消息写进队列,就有一个消息的序号,然后消费者消费了消息后,有一个定时任务,把自己消费过的消息offset提交一下,表示“表示我已经消费过了”,下次重启、宕机也好,在offset的序号位置继续消费即可。
但是万一,刚好消费了,没来得及offset重启了,就会有重复消费的问题了。
重复消费其实还好,如果是数据库插入就麻烦了。如果是订单类的消息,你要往数据库插入一条记录,重启了又插入了一条重复的消息记录,你有唯一的id主键,就会报错了,如果没有,就会有脏数据,那怎么办?
这就是幂等性的问题。
解决这个问题,还是得根据业务情况而定。
有几个解决思路:
- 你要插入数据库,那你可以先用主键查一下,如果有了就不要插入了,直接更新就好了,不然系统报错了(其实报错也比重复插入要好)。
- 可以利用Redis,因为Redis是天然的幂等性,set 值是否存在都会成功。给消息设置唯一id,消费前,可以先去Redis查一下,是否消费过。
# 5、消息如何保证可靠性?(丢失怎么办)
具体参考:https://www.jianshu.com/p/06e7e3b34dd6
丢失分三种情况,以RabbitMQ和kafka为例:
# 1、生产者丢失
a) RabbitMQ
RabbitMQ可以开启事务,这种方法称为事务机制,如果消息被mq拿到并且响应了,就提交事务,如果报错了,就可以回滚,然后重发。这种方法是同步的,必须要等mq的响应才行,太耗性能,吞吐量下降。
RabbitMQ还有一种异步机制,称为confirm模式,生产者开启confirm,每一个消息都有唯一id,你发送个消息之后就可以发送下一个消息,RabbitMQ 接收成功就回传一个ack接口,没能处理这个消息就调用nack接口。一般采用这种机制,而不是事务机制。
b) Kafka
(kafka中就是partition;rabbitMq中就是queue)
kafka可以设置参数,可以保证生产者、kafka 自身 消息不丢失。
-第一个:给topic设置replication.factor参数大于1,要求每个partition必须最少有两个副本.
第二个:在Kafka客户端min.insync.replicas参数大于1,要求每个leader最少感知到有一个follower还与自己保持联系,没有掉队.
第三个:在producer端设置acks=all,要求每条数据写入replica后,才认为写入成功.
第四个在producer端设置retries=MAX,写入失败,无限重试.
# 2、mq自己丢失
a)RabbitMQ
RabbitMQ自己弄丢了数据,一般少见。这种情况需要开启RabbitMQ 持久化机制,和Redis差不多,写入磁盘,重启的时候读取磁盘,恢复之前的数据,不过也存在没来得及持久化就丢失的情况。
RabbitMQ 这种持久化可以跟confirm机制结合,持久化到磁盘了,我才调用你ack接口。
# 3、消费者丢失
a) RabbitMQ
RabbitMQ 如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了、宕机了。这就需要ack机制了,就是说不要开启自动确认,我在代码里面处理完毕了,手动调用ack的api。
b) Kafka
Kafka有一个offset,消费者自动提交了 offset,kakfa就当你成功消费了,但当你正准备要处理这个消息,但没来得及,宕机重启了其实还没消费,消息就丢失了。
这个和RabbiMQ有点类似,关闭自动offset提交。
# 6、如何保证消息的顺序性?
1、单线程消费保证消息的顺序性
2、对消息进行编号,消费者处理消息是根据编号处理消息。
3、拆分多个 queue,每个 queue 一个 consumer。
这种还是要结合业务的,比如说你要发布文章、收藏。那你收藏消息先执行,可以加个判断是否文章存在,没有就显示失败,或者重试。
参考:https://www.jianshu.com/p/02fdcb9e8784
# 7、消息积压怎么办?
临时扩容。
参考:https://www.jianshu.com/p/07b2169bef49
# 8、Rabbitmq有哪些重要角色?
生产者:消息的创建者,负责创建和推送数据到消息服务器
消费者:消息的接收方,用于处理数据和确认消息
代理:就是RabbitMQ本身,用于扮演快递的角色,本身并不生产消息。
# 9、Rabbitmq有哪些重要组件?
ConnectionFactory(连接管理器):应用程序与RabbitMQ之间建立连接的管理器
Channel(信道):消息推送使用的通道
Exchange(交换器):用于接受、分配消息
Queue(队列):用于存储生产者的消息
RoutingKey(路由键):用于把生产者的数据分配到交换器上
BindKey(绑定键):用于把交换器的消息绑定到队列上
# 10、Rabbitmq 有几种广播类型?
三种广播模式:
fanout: 所有bind到此exchange的queue都可以接收消息(纯广播,绑定到RabbitMQ的接受者都能收到消息); direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息; topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息;
# 11、获取消息的模式
两种:
push:客户端与服务器建立连接后,当服务器有消息时,服务器将消息推送到客户端。
pull:客户端不断轮询请求服务端,来获取新的消息。
RocketMQ中都是采取消费端主动拉取的方式,即consumer轮询从broker中拉取消息。
MQ的消息消费方式是拉取消息的方式,消息消费有两种消费方式:广播模式与集群模式。
广播模式:每一个消费方式去拉取订阅主题下所有消息队列的消息。
集群模式:在集群模式下,同一个消费组内,有多个消费者,同一个主题存在多个消息队列,消息队列负载,通常的做法是同一个时间内只允许被一个消费者消费,一个消费者可以同时消费多个消息对列。
