 对读写分离的理解,为什么要读写分离?
对读写分离的理解,为什么要读写分离?
# 1、读写分离是什么
读写分离。
基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。
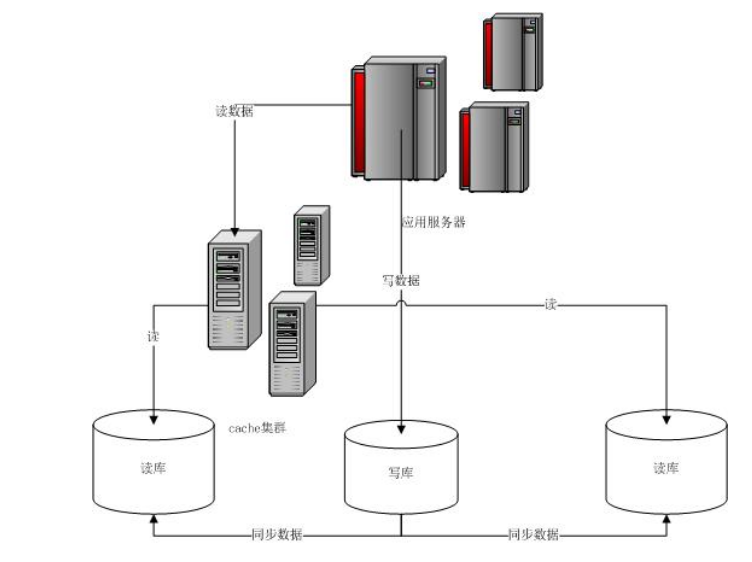
主库和从库之间会进行数据同步,以保证从库中数据的准确性。
比如说 微信朋友圈,大家都是刷朋友圈比较多,而发朋友圈很少,那么刷新朋友圈操作就可以查读库,发布朋友圈就可以操作写库。
单表数据量激增,还可以使用分库分表;读写分离依然无法解决单表数据量庞大的瓶颈问题,分库分表是个不错的选择。
读写分离侧重解决的是数据库并发问题产生的IO瓶颈(select)问题。
# 2、为什么要读写分离
优点:
1、随着数据数据量的增多,同时读写的操作也随之增多,单表达到一定数量后数据库性能就会下降,读写分离拆分读写功能,这样对于提升数据库的并发非常有效。
2、主从只负责各自的写和读,极大程度的缓解X锁和S锁争用。
update和delete会被这些select访问中的数据堵塞
3、不同地区的读有延迟,比如说机房在北京,请求在广州,ping延迟较大,假如广州也有从库,这样用户延迟会更低。
4、可以在从库启动是增加一些参数来提高其读的性能,例如--skip-innodb、--skip-bdb、--low-priority-updates以及--delay-key-write=ALL。这样从库的配置就更独立了。
缺点:
以一主多从为例,主库负责写,从库负责读,主库的数据同步到从库是需要时间,从库就会读到的数据就会延迟,就会产生数据不一致的问题;这也是常说的主从同步延迟。
用了mysql主从架构之后,可能会发现,刚写入库的数据结果没查到,结果就完蛋了。
所以,MySQL主从如何同步是读写分离需要考虑的事情。
# 3、主从同步延迟如何解决?
主从同步延迟是必然现象,这需要结合业务一起选取方案。
主从同步原理:(这个需要知道,也是常问的)

- Master 数据库只要发生变化,立马记录到Binary log 日志文件中
- Slave数据库启动一个I/O thread连接Master数据库,请求Master变化的二进制日志
- Slave I/O获取到的二进制日志,保存到自己的Relay log 日志文件中。
- Slave 有一个 SQL thread定时检查Realy log是否变化,变化那么就更新数据
# 1、强制读主库
如果是实时性要求高,比如说转账,转账成功插入一条流水到主库,然后用户立即刷新页面,此时是查询,这个时候如果主从延迟就很很麻烦了,用户会误以为钱不见了。
这种情况可以强制读主库,虽然会增加主库的压力但为了业务也是迫不得已的选择。
# 2、延迟读取
既然主从存在延迟,干脆就延迟读算了,比如说估量主从延迟大概在1s,代码里面强制2s后再查询从库数据,比如说贴吧发帖,发帖成功后,前端做一个刷新中的提示,这种情况要取决于用户的容忍度。
# 3、切换同步方式
主从同步MySQL有三种方式:
异步方式:MySQL 提交事务的线程完全不关心 binlog 是否已经同步到从库,事务执行完成就会返回客户端响应结果,这种模式如果主库宕机,数据存在丢失的风险;
同步方式:MySQL 提交事务的线程会等待所有从库 binlog 同步成功的响应,这种情况不存在丢数据的情况;
半同步方式:MySQL 5.7 版本之后增加的功能,MySQL 提交事务的线程不会等待所有从库 binlog 同步成功的响应,只要有一部分从库同步成功,它就会返回客户端响应结果。
# 4、利用缓存
插入新的数据后,同时缓存一条数据到Redis,前端查询从缓存里面读取数据。
貌似微博就是这样做的
还有另外的原因会影响主从延迟,比如:
- 从库太多,主库binlog同步到多个从库上, IO会是个问题,大量的同步会消耗主库的资源,这也会违背主从同步的思想。
- 从库的服务器CPU经常爆高,也会影响同步。
# 4、读写分离的实现和策略有哪些
读写分离的落实过程:
1、 搭建主从,一般的生产搭建一主两从,不宜太多。master负责写入数据,两台slave负责读取数据
2、确保主从同步没问题,选用主从延迟策略
3、把读写操作分发到不同的库。
上面都提到了第1、2 两点,下面来看看目前的第三点分发策略有哪些:
代理方式:
MySQL Router(官方)、Atlas(基于 MySQL Proxy)、Maxscale、MyCat。
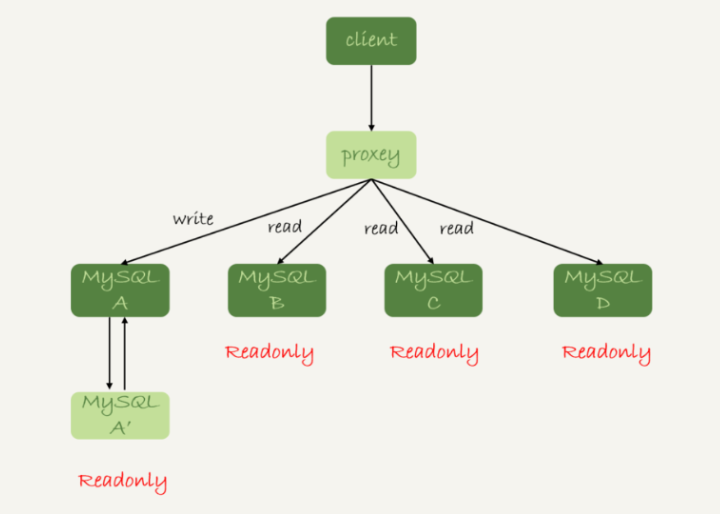
上图中A' 是 A 的 备库,万一主库A挂了,备库A' 可以替代。
proxy作为代理层,请求都由这个代理层处理,代理层负责读写,然后分发到不同的数据库;但对proxy的维护成本较高,架构复杂。
第三方组件:
sharding-jdbc
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
sharding-jdbc 有一个主从延迟以解决数据不一致性的方案:
同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性
sharding-jdbc 官方文档:http://shardingsphere.apache.org/
# 5、读写分离的其他方案
数据库出现性能瓶颈才会考虑读写分离,评判的标准有很多,比如连接数不够导致阻塞,慢日志发现SQL操作很慢。
但是个人不建议一上来就分库分表,可以先看一下MySQL的B+树,在数据有索引的情况下,一个千万量级,且存储引擎是MyISAM或者InnoDB的表,其索引树的高度在3~5之间,而达到千万级的表的业务又有多少呢?
所以首先要从表出发,对表结构进行优化、SQL调优、加索引是应该先考虑的。
再者是引入中间件,比如Redis缓存、比如有些操作日志利用消息队列异步请求到数据库。
如果真的优化到没东西优化了然后才上集群,才加机器,最后再考虑读写分离,读写分离之后顶不住就再分库分表。
