 对分库分表的理解,为什么要分库分表?
对分库分表的理解,为什么要分库分表?
上一篇文章对读写分离的理解,为什么要读写分离? 说到了读写分离的好处,可以解决MySQL的性能问题。
文末留了个问题,读写分离并不是万能的,读写分里侧重解决的是数据库并发问题、IO瓶颈(select)问题。
但是你想想看,读写分离它的数据还是存储在各自的库的,并没有解决数据激增的问题,当一个表过大了,当数据激增,单表查询已经到达了瓶颈,这种情况就不能用读写分离解决了,这种情况就要考虑集群+分库分表。
这篇文章就来聊聊分库分表。
在聊分库分表的时候,先抛出几个问题:
1、为什么要分库分表?标准是什么?
2、你知道一张表到达什么样的数据量才需要分库分表吗?
3、除了分库分表,就没有其他办法了吗?
# 1、为什么要分库分表,评判标准是什么?
通过读写分离我们解决了许多瓶颈问题,比如说大量请求阻塞、SQL查询慢。
但随着数据量越来越大,存储成了一个很大的问题,比如说好几亿的数据都在一张表,无论你怎么读写分离,IO都达到了瓶颈,简单的方法就是提升机器性能,但是成本高,而分库分表会是一个很好的选择。
所以分库分表的原因无法就是数据库出现性能瓶颈,承受不住压力了。
常见原因有:
- 大量请求阻塞,update等待select
- 表大,SQL查询慢
- 数据量激增,IO、网络出现瓶颈
评判的标准是什么呢?
在中国互联网技术圈流传着这么一个说法:MySQL 单表数据量大于 2000 万行,性能会明显下降。
InnoDB一棵B+树可以存放约2千万行数据
事实上,这个传闻据说最早起源于百度。具体情况大概是这样的,当年的 DBA 测试 MySQL性能时发现,当单表的量在 2000 万行量级的时候,SQL 操作的性能急剧下降,因此,结论由此而来。然后又据说百度的工程师流动到业界的其它公司,随之也带去了这个信息,所以,就在业界流传开这么一个说法。
再后来,阿里巴巴《Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。毕竟阿里代表着最新前沿的权威,所以,很多人设计大数据存储时,多会以此为标准,进行分表操作。
感兴趣的可以读一下阿里巴巴的《Java 开发手册》
个人感觉这本指南就是:快速上车,避免踩坑
这里这是业界的经验,具体还是要结合业务和服务器性能一起评判。
# 2、一个B+树能存放多少行数据
这是个题外话,一般不会引申。
InnoDB存储引擎最小储存单元——页(Page),一个页的默认大小是16K。
默认的16KB或更大的页面大小适用于各种工作负载,特别是涉及表扫描的查询和涉及批量更新的DML操作
MySQL 5.7增加了对32KB和64KB页面大小的支持。
可以进行设置:
mysql> show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
可以看一下你的表或者你的data目录下的.ibd 文件,它们都是16的倍数。

数据表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?假设一行数据的大小是1k,那么一个页可以存放16行这样的数据。
但是我们知道在B+树中,叶子节点存放数据,非叶子节点存放键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据;
而在实际应用中,大部分是以bigint作为主键的,主键ID为bigint类型长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16384/14=1170。
MySQL中类型占用大小:
tinyint 1 smallint 2 mediumint 3 int 4 bigint 8
那么可以算出一棵高度为 2 的B+树,能存放1170*16=18720条这样的数据记录。
3 个高度的B+树就是1170*1170*16=21902400 ,2 千万左右。
如果是int类型的主键,int占用 4 字节,3 个高度的就是大概就是 4 千万的数据。
而 int 的自增id最大值也恰好差不多是 4 千万,所以还是分表吧,不然id用完了就无法插入了。
那么如果有一张表行数是一千万,那么他的B+树高度依旧是3,查询效率仍然不会相差太大。
所以Innodb选用B+树作为索引,而不是B树,因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
# 3、分库
传统的业务常见的情况:
- 单应用单数据库
- 多应用单数据库
这两种是常见的架构模式,因为这样的数据库只有一个,逻辑简单。
但分库嘛,就是要做到:
- 多应用多数据库
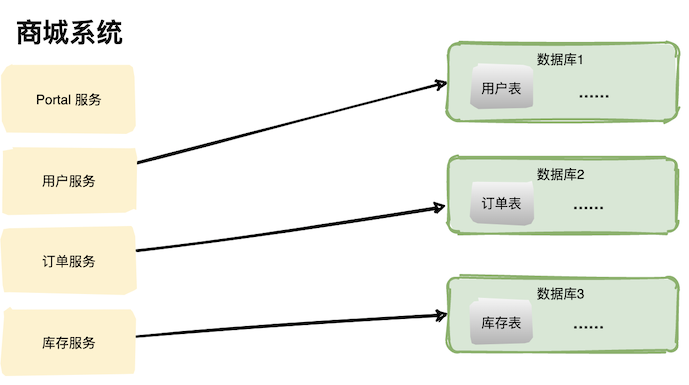
每个不同的模块对应不同的数据库,这是分库的最基本的操作,依据业务模块进行分库。
# 4、分表
根据500w行数的分表策略,又可以分为
- 垂直拆分:基于表或字段划分,表结构不同。
- 水平拆分:基于数据划分,表结构相同,数据不同。
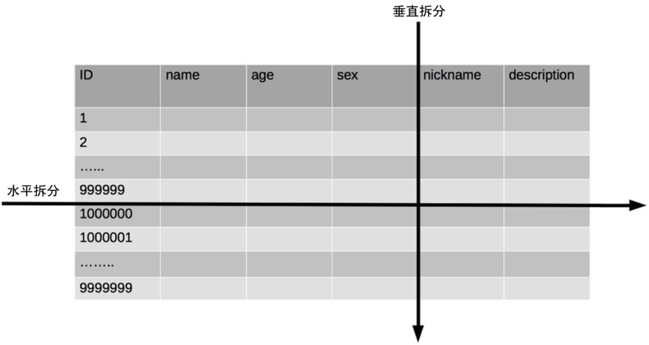
以上面的表为例,user表中一共有 6 个字段:id,name,age,sex,nickname,description,
垂直拆分:
如果 nickname 和 description 不常用,我们可以将其拆分为另外一张表:用户详细信息表,这样就由一张用户表拆分为了用户基本信息表+用户详细信息表,两张表结构不一样相互独立。
但垂直拆分并没有从根本上解决单表数据量过大的问题,这时候还是得依靠水平拆分。
水平拆分:
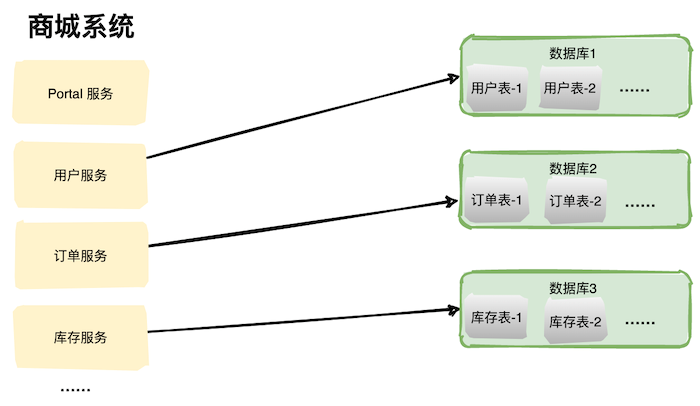
水平拆分的方式有很多,常见的有求余,如果表中有500万条数据,我们拆分为两张表,id 为奇数的:1,3,5,7……放在 user1 中;id 为偶数的:2,4,6,8……放在 user2 中,这样的拆分办法就是水平拆分了。
还可以按照时间维度去拆分,比如每日、每月等进行拆分。
# 5、分库分表有没有什么比较推荐的方案?
ShardingSphere 、mycat
这些都是成熟的方案了,不用自己造轮子。
# 6、分库分表带来的问题有哪些?
join 操作 :同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
事务问题 :同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。
分布式 id :分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 id 了。
# 7、除了分库分表,还有其他方法吗?
读写分离、分库分表 都是庞大的工程,对业务逻辑性影响较大。
除了分库分表外,还可以从以下方法进行一步一步优化:
- SQL优化
- 表结构优化
最后还可以选用一些高性能的数据库,比如TiDB,TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。TiDB 是一个分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。
