 可观测系统在Flyme落地
可观测系统在Flyme落地
加入Flyme团队之初,团队尚未建立可观测性的概念。彼时,各业务方主要关注传统的业务指标,如销量、DAU、转化率等;部分业务虽已采用侵入式埋点,但整体呈现各自为战、标准不一的局面。
随着业务体量的快速增长,运维复杂度、观测深度以及告警时效性的需求急剧上升,传统的监控手段已难以支撑。此时,虽然市面上已有如Datadog、ARMS等成熟的可观测性解决方案,但其接入成本较高,且与内部技术栈的适配存在一定门槛。
基于此背景,我开始主导自研可观测性系统的落地,旨在构建统一、低成本、高适配的观测体系,以支撑业务的持续演进。
# 方案
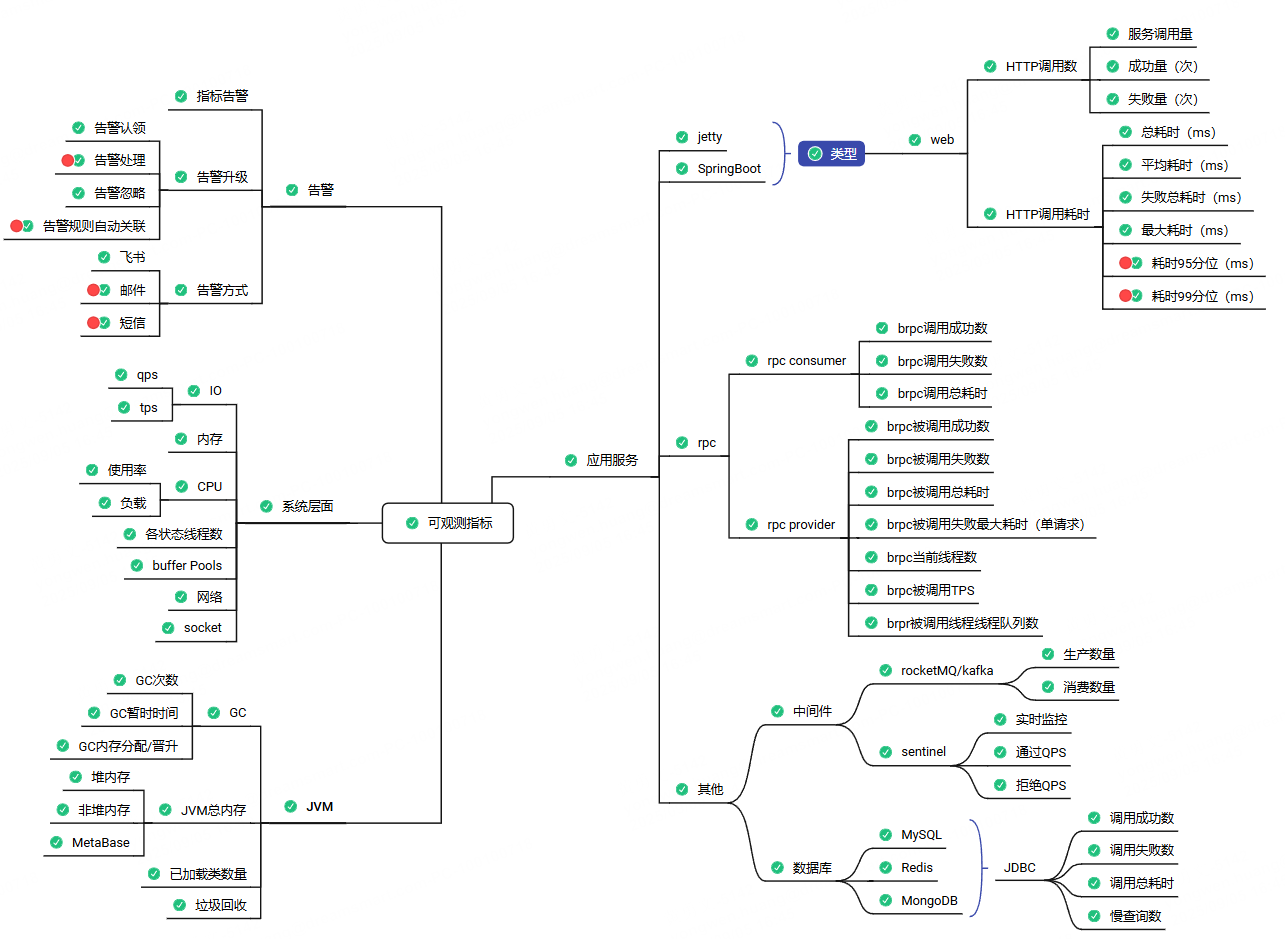
通过梳理业务使用基础中间件的版本,我们确定基础的可观测指标,如下图所示。
# 演进1 - zabbix
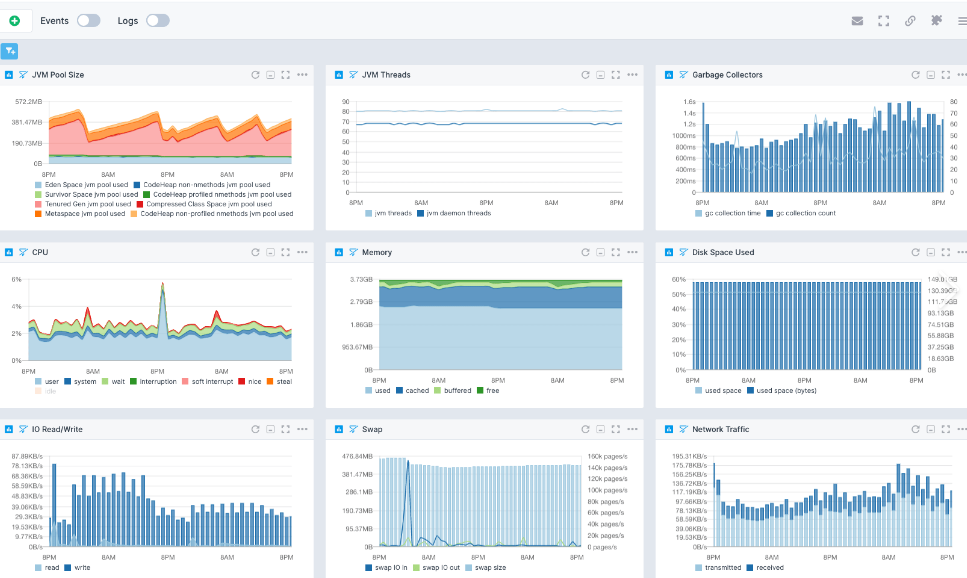
运维团队已使用zabbix对理物理机、交换机、防火墙等强状态、低频变化的硬件监控,在表现上已经是非常出色。
但面对Java应用程序而言,开发者需要额外开启 JMX 端口或安装 Zabbix Agent,且 JMX 本身开销较大,协议过重而且仅仅支持JVM相关监控,不是很符合我们的要求,遂放弃这个方案。
而且笔者还发现一个问题,Zabbix Agent 像“洪水”一样主动推数据,Agent 上报数据后,Server 需要处理逻辑(触发器检查、趋势计算),然后写入MySQL,数据库的 I/O 写入压力十分大,而且 zabbix Server 容易被淹没。
# 演进2 - skywalking
笔者在调研可观测那一年,skywalking 非常火,可以说是可观测免费开源项目的天花板了。
此时笔者还调研过阿里云的 ARMS、dataDog,了解它们收费模式, 这样看 skywalking 也不是不能用哈哈,虽然开源版的 skywalking 的功能相对收费版来说少一些,但是作为一个成熟的应用可观测系统,已经完全可以覆盖常见的指标了。
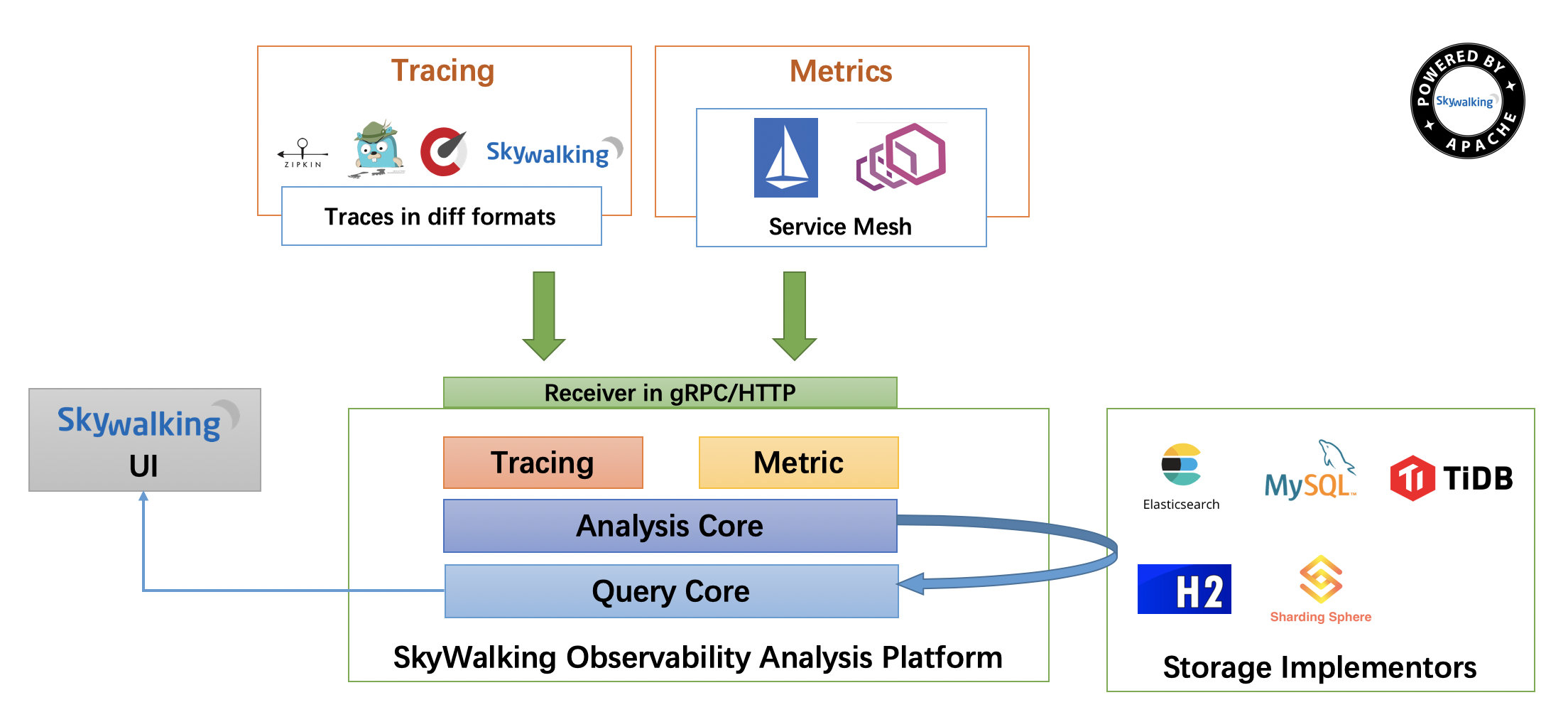
整个架构,分成上、下、左、右四部分:
考虑到让描述更简单,我们舍弃掉 Metric 指标相关,而着重在 Tracing 链路相关功能。
- 上部分 Agent :负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。而我们目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给服务器。
- 下部分 SkyWalking OAP :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
- 右部分 Storage :Tracing 数据存储。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器。而我们目前采用的是 ES ,主要考虑是 SkyWalking 开发团队自己的生产环境采用 ES 为主。
- 左部分 SkyWalking UI :负责提供控台,查看链路等等。
其次对业务方接入也非常友好,只需要在程序启动前指定 -javaagent:skywalking-agent.jar 参数即可,不到1分钟就可以在 控制台 看到相关的指标了:
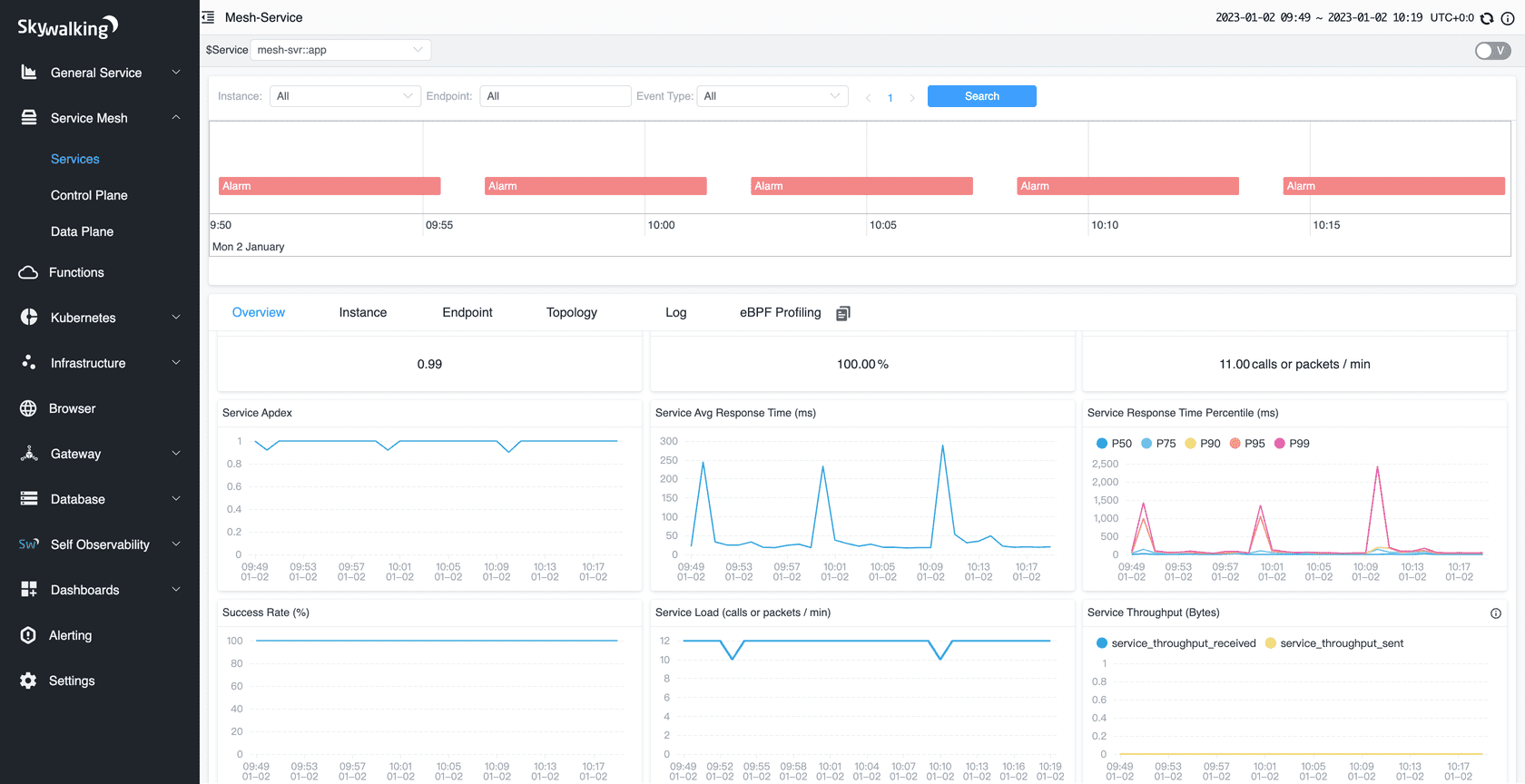

此时是笔者第一次接触到 javaagent 字节码侵入 技术,在无须改动任何代码的情况下,应用只需要简单命令即可接入,对业务方来说,这完全是可接受的。
不过使用了skywalking后,也出现了不少问题:
- skywalking 只对基础组件特定的版本做埋点,团队一些自研的框架如 rpc 则无法切入,这需要我们手动开发
- 对日志、链路 来说,业务还需要额外接入skywalking sdk ,这样对业务来说是难以接受的
- 日志、链路 的存储是一个瓶颈,笔者此前试过使用 MySQL/elasticsearch 作为存储引擎,但是在使用TraceID串联日志的时候,性能还是稍慢的
# 演进3 - 自研javaagent
市面上成熟的Java可观测方案都是基于 javaagent 实现,如上述说的 skywalking,完全可以借鉴它们的思想,自主开发一个更贴合业务需求的javaagent。
# javaagent设计
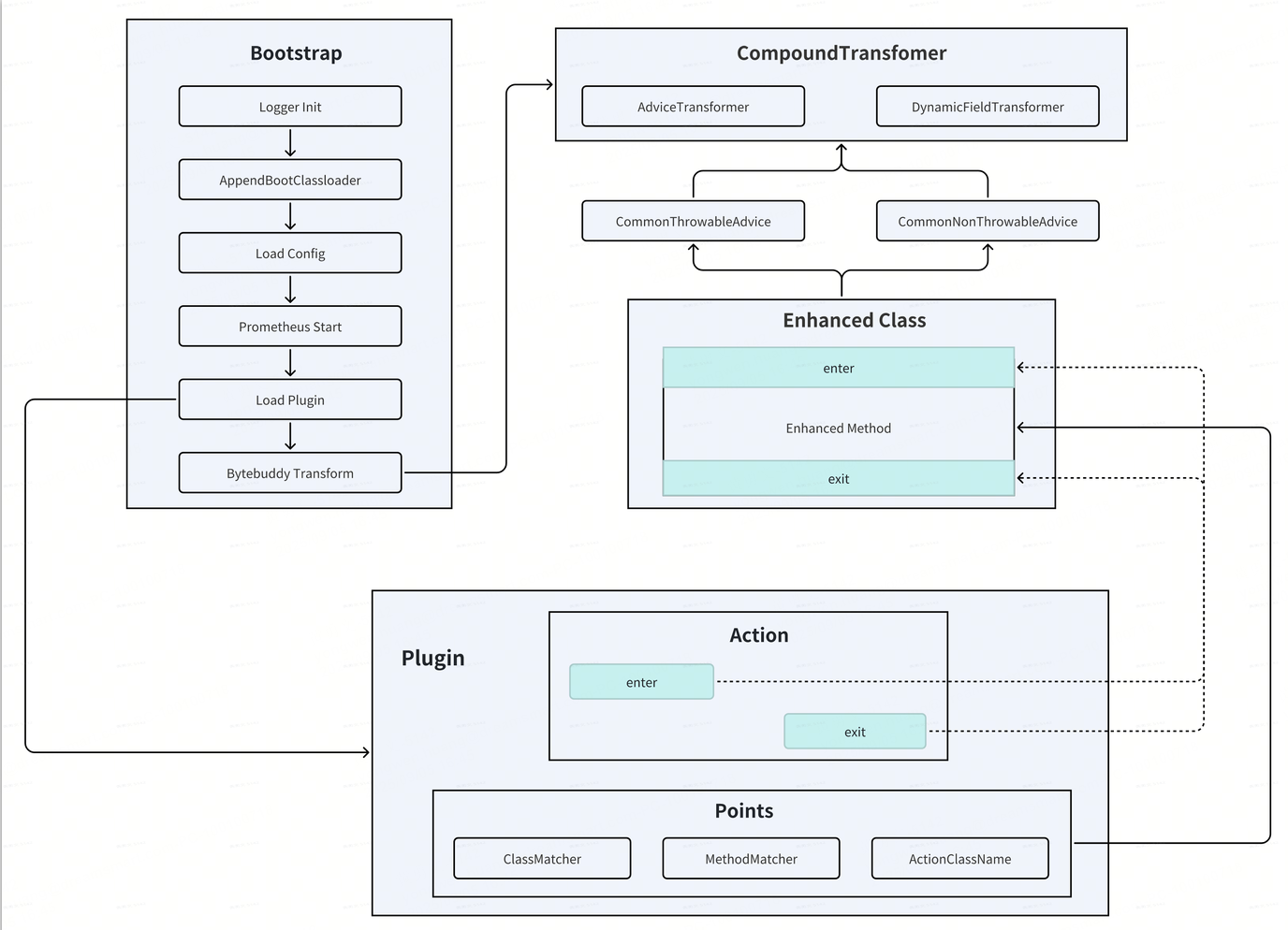
字节码增强工具选择使用 bytebuddy ,相比ASM、javassist 可读性更强,而且最重要的是debug调试更容易。
在使用javaagent的时候,要注意以下两个点:
- 插件应该以独立的形式存在,可以自定义 ClassLoade加载r, 确保运行时隔离(动态隔离)
- 依赖应该足够少,受主应用影响存在包冲突的情况下,可以考虑
maven-shade-plugin
# 可观测框架选择
笔者开始思考如何收集指标,同时了解到可观测分为三大块:
- Metrics指标
- Tracing链路
- Log日志
此时团队已经开始使用 prometheus,Metrics指标 如果通过javaagent 以prometheus的格式暴露,最后通过prometheus sever 拉取应该也是可以的。
OpenTelemetry 可观测性的框架和工具包,是开源的,并且与供应商和工具无关,这意味着它可以与各种可观测性后端配合使用,包括prometheus,所以毫无疑问选择 OpenTelemetry 作为工具包。
Tracing链路 同理通过切面,在入口层(一般是HTTP或者RPC)织入,通过上下文传递。
Log日志 通过对三大日志框架(logback、log4j、log4j2)进行埋点,上下文获取到TraceID后,跟新日志属性。
目标:Metrics指标、Tracing链路、Log日志 只使用一个javaagent 实现收集。
# OpenTelemetry
OpenTelemetry(也称为 OTel) 提供了一个开源标准和一组技术,用于捕获和导出云原生应用和基础架构中的指标、跟踪记录和日志。OpenTelemetry致力于如何收集和发送可观测能力数据并使其具有通用格式。OTel 旨在提供与供应商无关的统一库和 API 集——主要用于收集数据并将其传输到某个地方。
OpenTelemetry提供了跨语言的标准规范,包括数据、Context、API、概念等的统一。在此基础上,还提供了收集器(Collector)、SDK、开箱即用的探针(Agent/Instrument)。
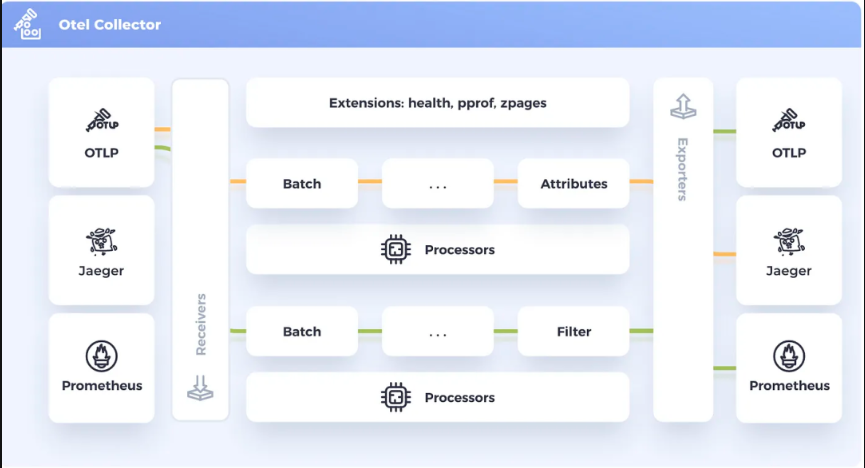
# 完整架构图
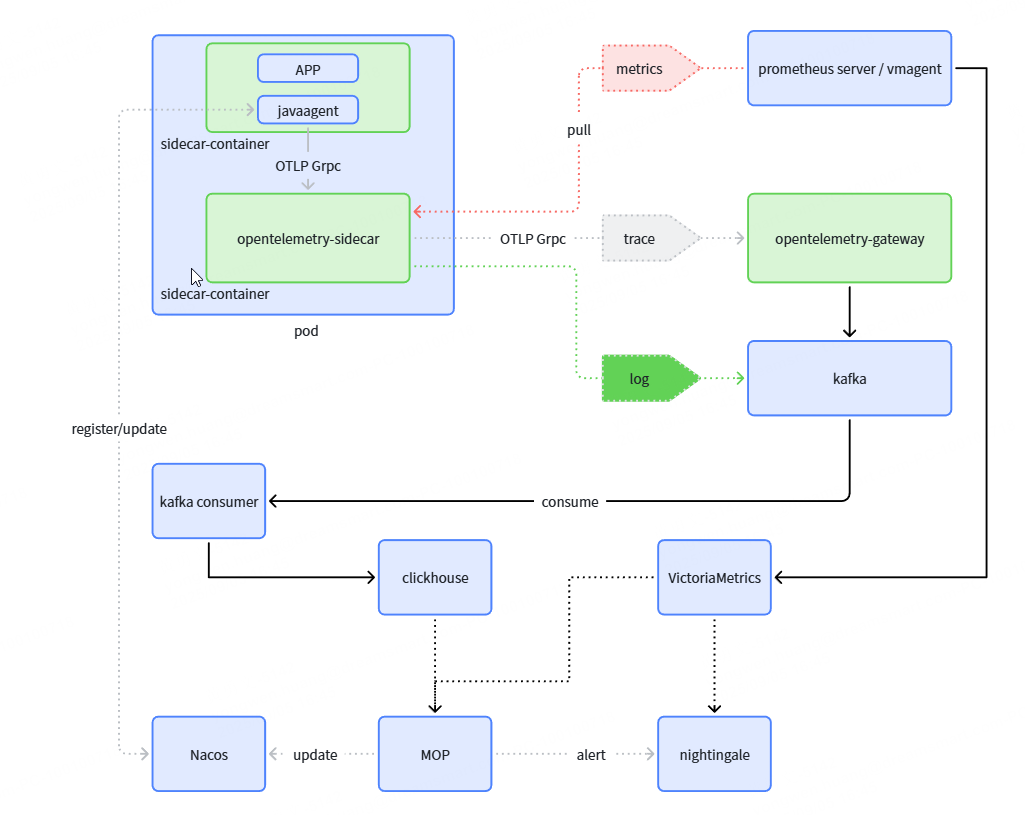
组件说明:
| 组件名称 | 主要作用 | 组件描述 |
|---|---|---|
| javaagent | 负责Log/Metrics/Trace可观测数据收集 | 自研的Java Agent,无侵入方式与业务应用集成,开箱即用 |
| Otel-Collector Sidecar | 负责接收One-Agent推送过来的数据,对其进行预处理 | 业务应用的sidecar,和业务应用部署在同一个pod里面,主要作用为数据格式转换、数据预处理、架构优化等 |
| OpenTelmetry-SDK | 业务自定义埋点SDK | 给业务用用自定义埋点使用的SDK,目前包括Java和Python语言 |
| Otel-Collector Gateway | Trace数据集中收集、采样、处理 | 集群方式部署,负责Trace数据的采样、处理、导出等功能 |
| Prometheus/Vmagent | Metrics数据的拉取器 | 发现业务应用的metrics端点,并拉取监控数据,最后写到远程时序数据存储 |
| ClickHouse | Log/Trace数据落地的地方 | Log/Trace数据最终落地的组件,供可观测平台查询分析 |
| VictoriaMetrics | Metrics数据落地的地方 | Metrics数据最终落地的组件,供可观测平台查询分析 |
| kafka consumer | kafka消费者 | 消费kakfa中的日志、链路,并落库到clickhouse |
| MOP | 可观测平台控制面和控制台 | 可观测平台,拓补依赖、指标分析、日志查询、链路聚合 |
| nightingale | 监控告警基础平台 | 监控告警平台,规则计算引擎、告警消息触达、监控大盘展示 |
| Nacos | One-Agent注册,Agent配置推送 | 主要用来协助可观测平台控制面下发Agent配置,对Agent进行管控 |
关于如何动态控制相关配置,解决方案是引入了 nacos 作为控制中心
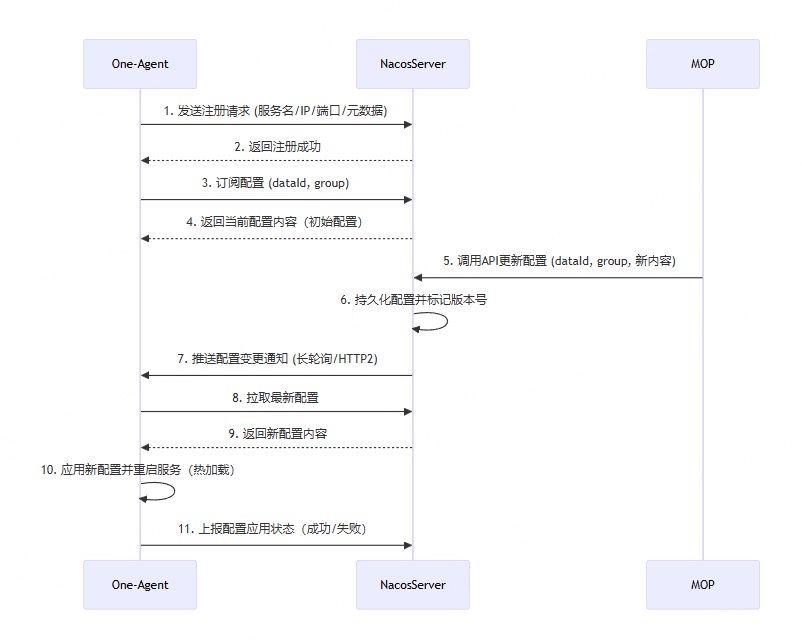
# 两层otel-collector
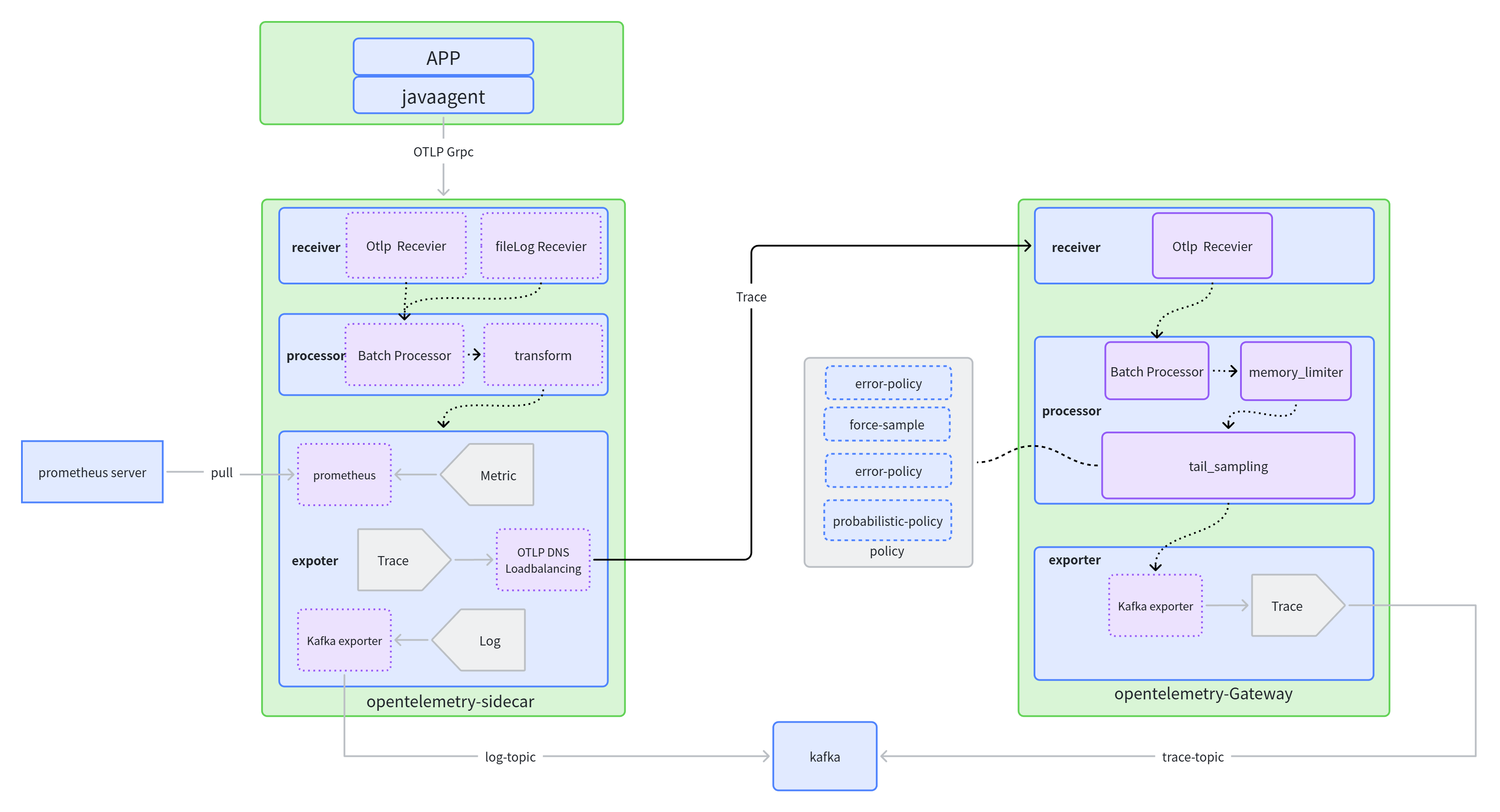
- 在可观测平台技术架构中,使用了两层收集器的部署方式。第一次层是应用层side otel-collecor,第二层是网关层gateway otel-collector。使用两层收集器的原因是:
- 解耦。应用层收集器应由服务应用团队维护和配置,包括应用服务的个性化需求配置等。假设一个场景,业务应用需要对某个重要业务接口的链路数据的tag进行敏感信息处理,collector的processor就是处理这个事情的(修改、过滤、清理等),如果只存在一层网关gateway otel-collector的情况下,那么网关层的processor配置势必会和N个应用配置相互耦合,不同应用修改配置,网关层频繁的reload配置重启,给系统的整体稳定性带来很大的影响。
- 采样处理。
跨应用调用下,各应用如何确保在agent侧标识该链路必须采样呢?
首先,入口类产生TraceId,无论是否采样,都会生成TraceId进行传递,在输出到Exporter的时候,如果是非采样,就直接丢弃,不会发送。
- 此时SDK可以采取采样控制,如 采样率(一般都是100%)、URL匹配等等。
其次跨应用下,one-agent采用的是继承parent traceId 策略。W3C标准 会带上 patent TraceId(traceId、spanId、traceId采样标识 三者组成)
恰好父、子 应用都采样,otel-sidecar 通过DNS发现otel-collector-gateway列表,otel-sidecar 根据traceId路由都会转发到同一个otel-collector-gateway。
Otel-collector-gateway 尾采样的情况下,根据采样策略对一批TraceID进行过滤(以TraceId为单位,命中就全采样,不命中就全废弃)
- 同时也可以对特定的attribute、resource 进行必采样,这里可以在javaagent通过nacos下发的配置,染色必须采样的请求。
processors: tail_sampling: decision_wait: 10s num_traces: 50000 expected_new_traces_per_sec: 1000 policies: [ { name: force-sample, type: boolean_attribute, # always sample if the force_sample attribute is set to true boolean_attribute: { key: agent.force.sample, value: true } } ]
- 同时也可以对特定的attribute、resource 进行必采样,这里可以在javaagent通过nacos下发的配置,染色必须采样的请求。
# 可观测平台
以上流程走通后,指标成功存储在时序数据库 VictoriaMetrics,而日志、链路 则存储在 clickhouse。
既然已经有数据了,那么做成一个一站式集指标、链路、日志、告警 一体的可观测后台就很简单了。
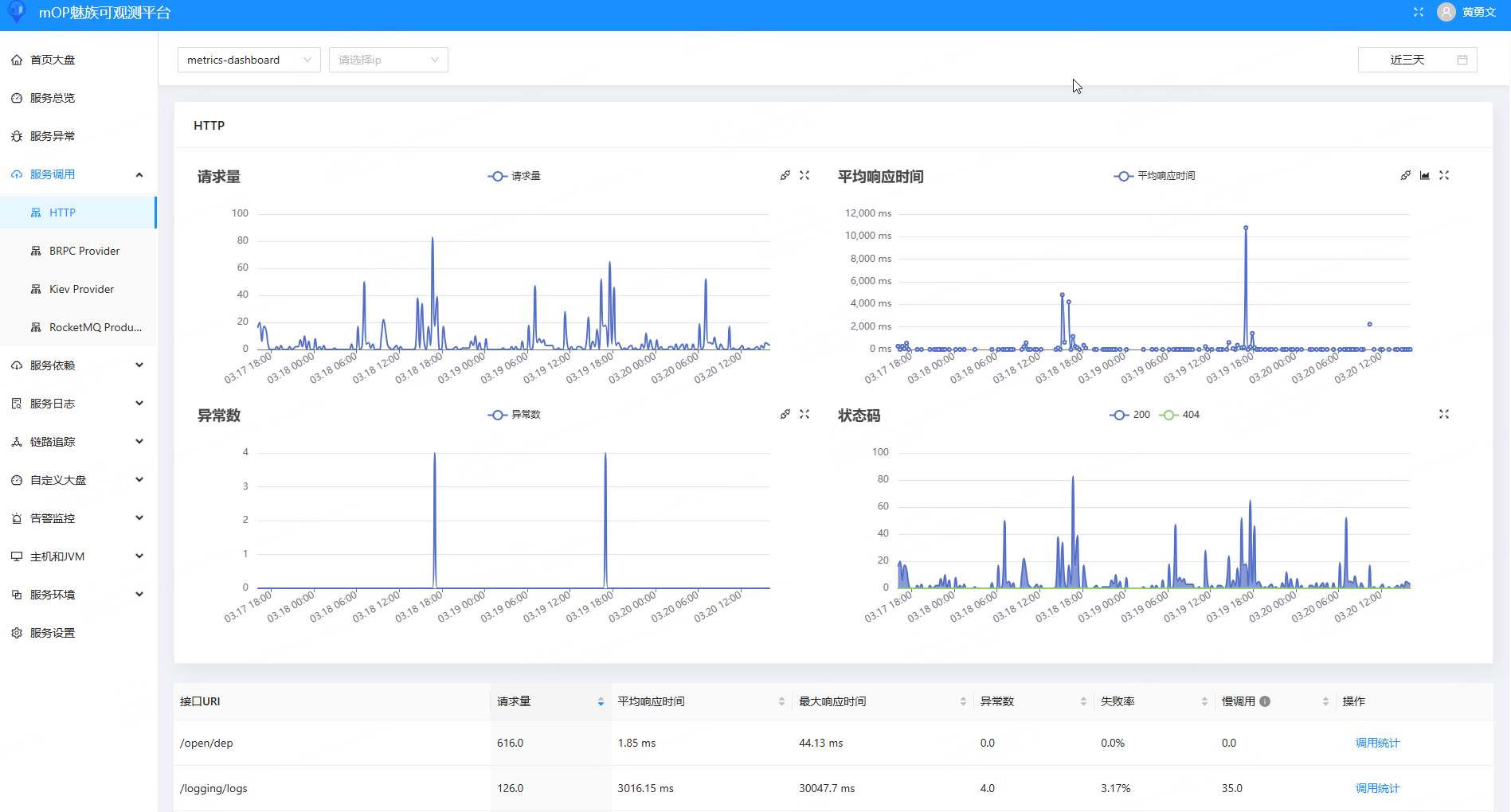
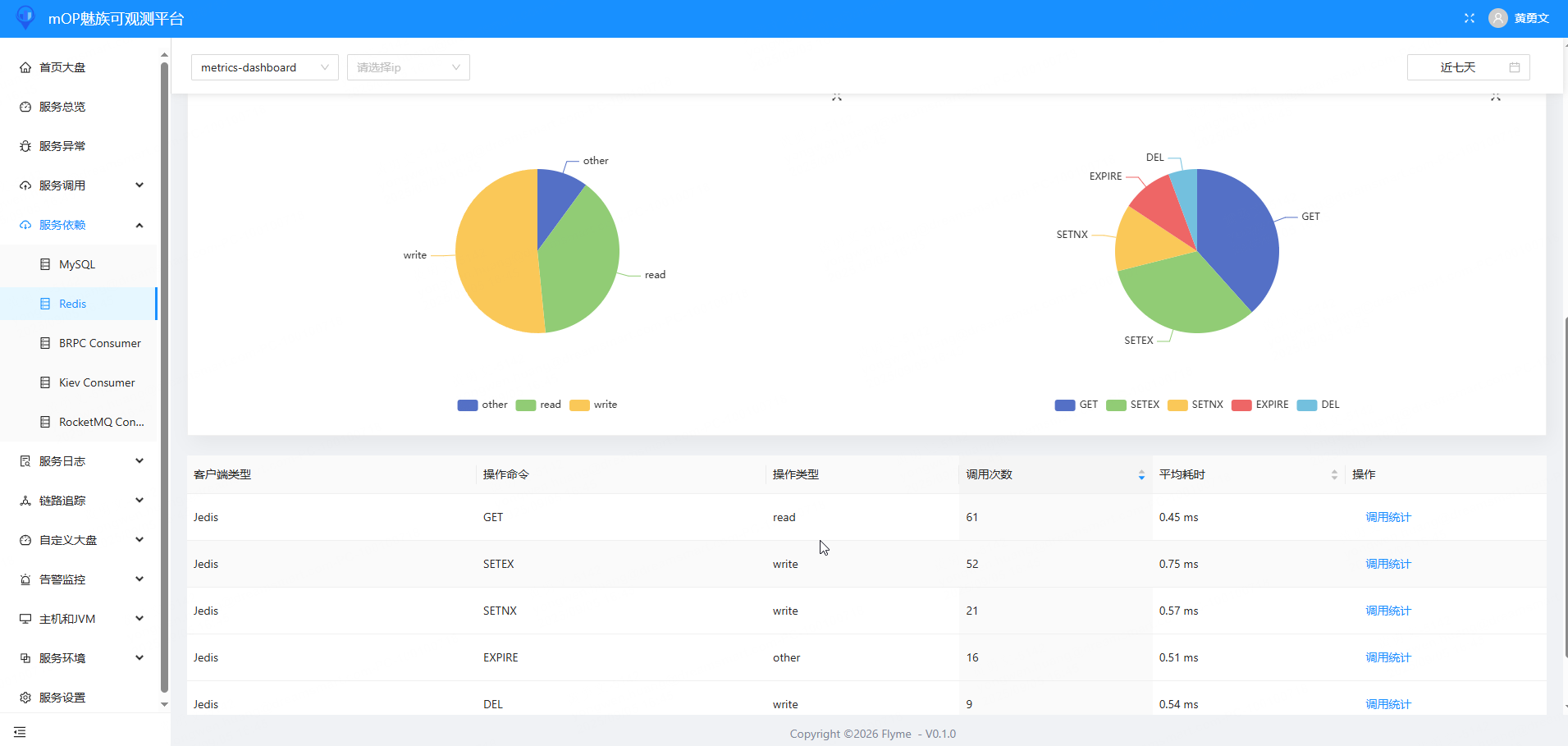
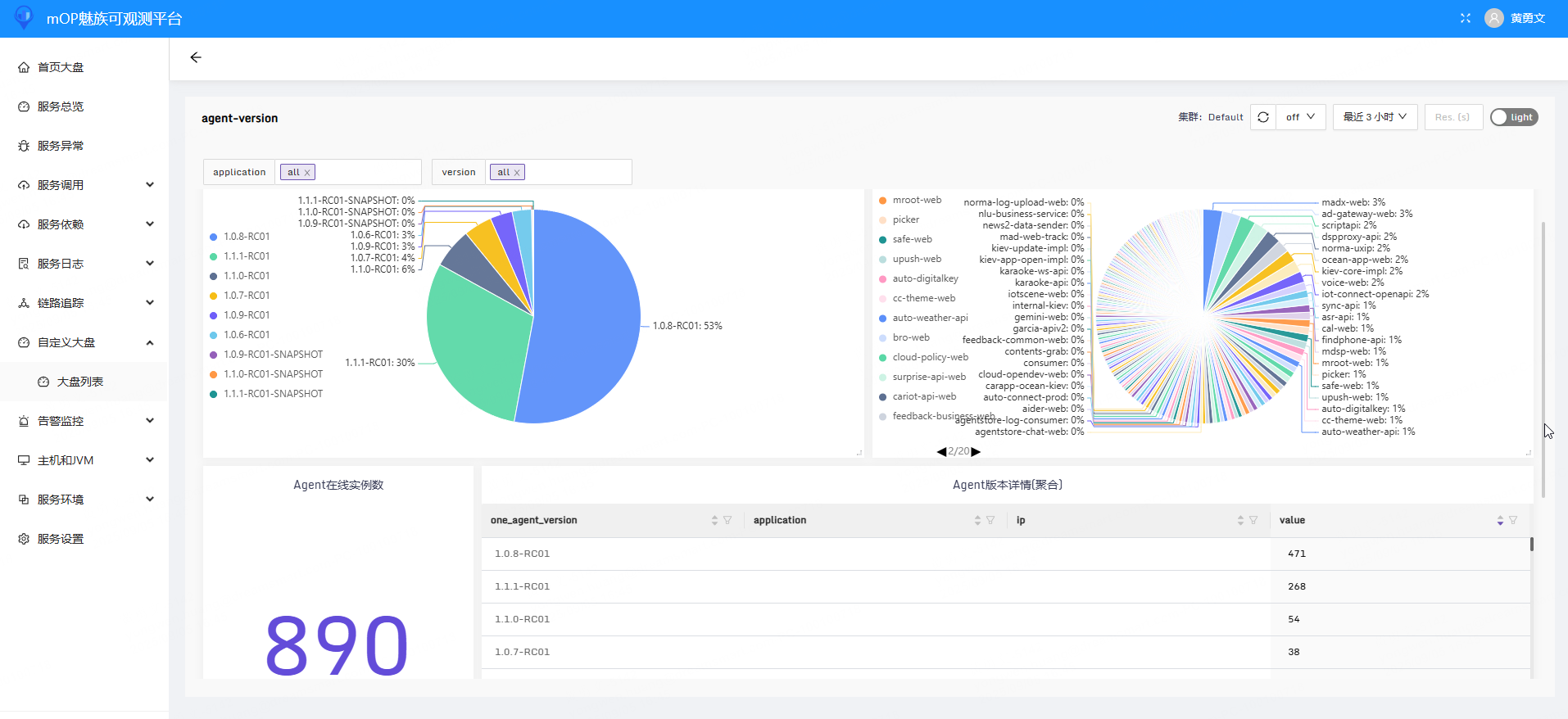
指标:
日志:
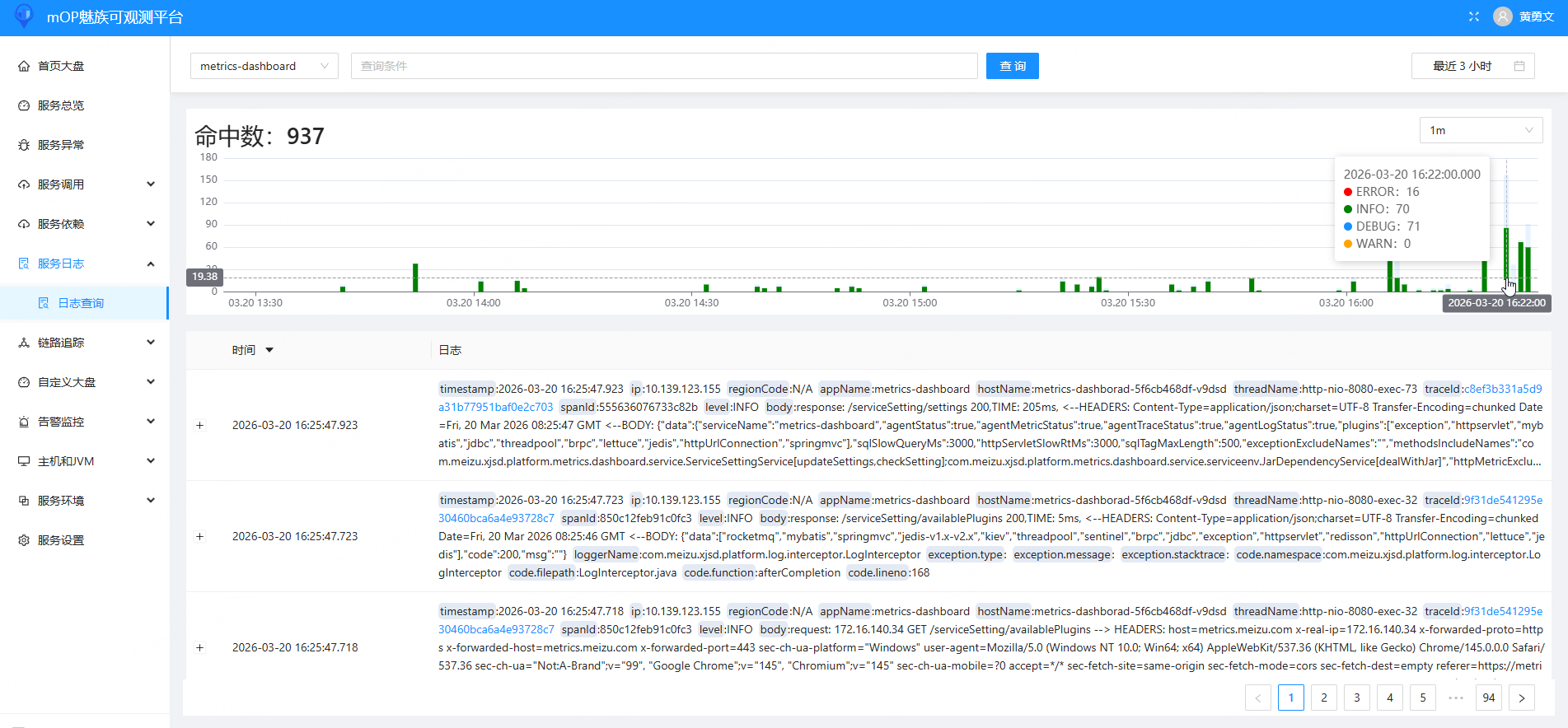
链路:
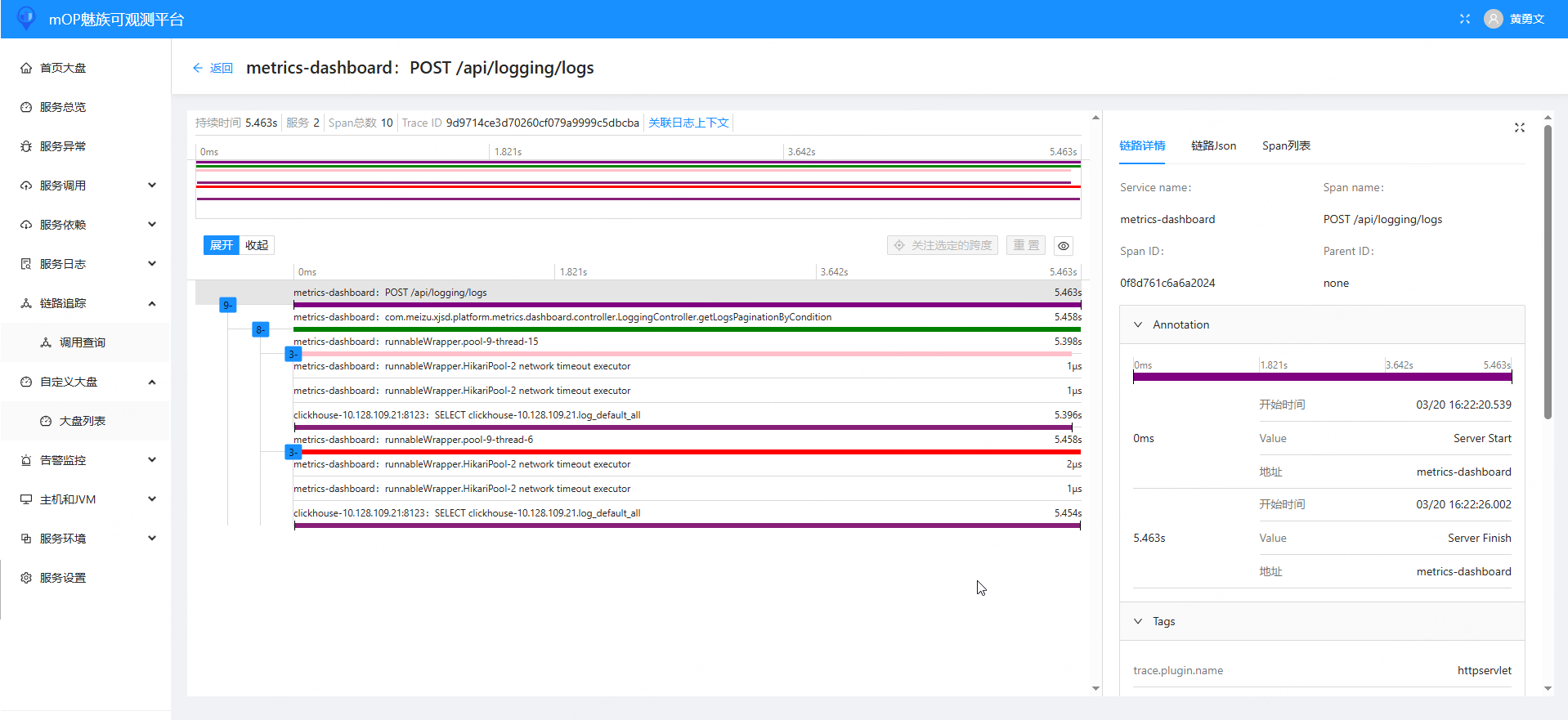
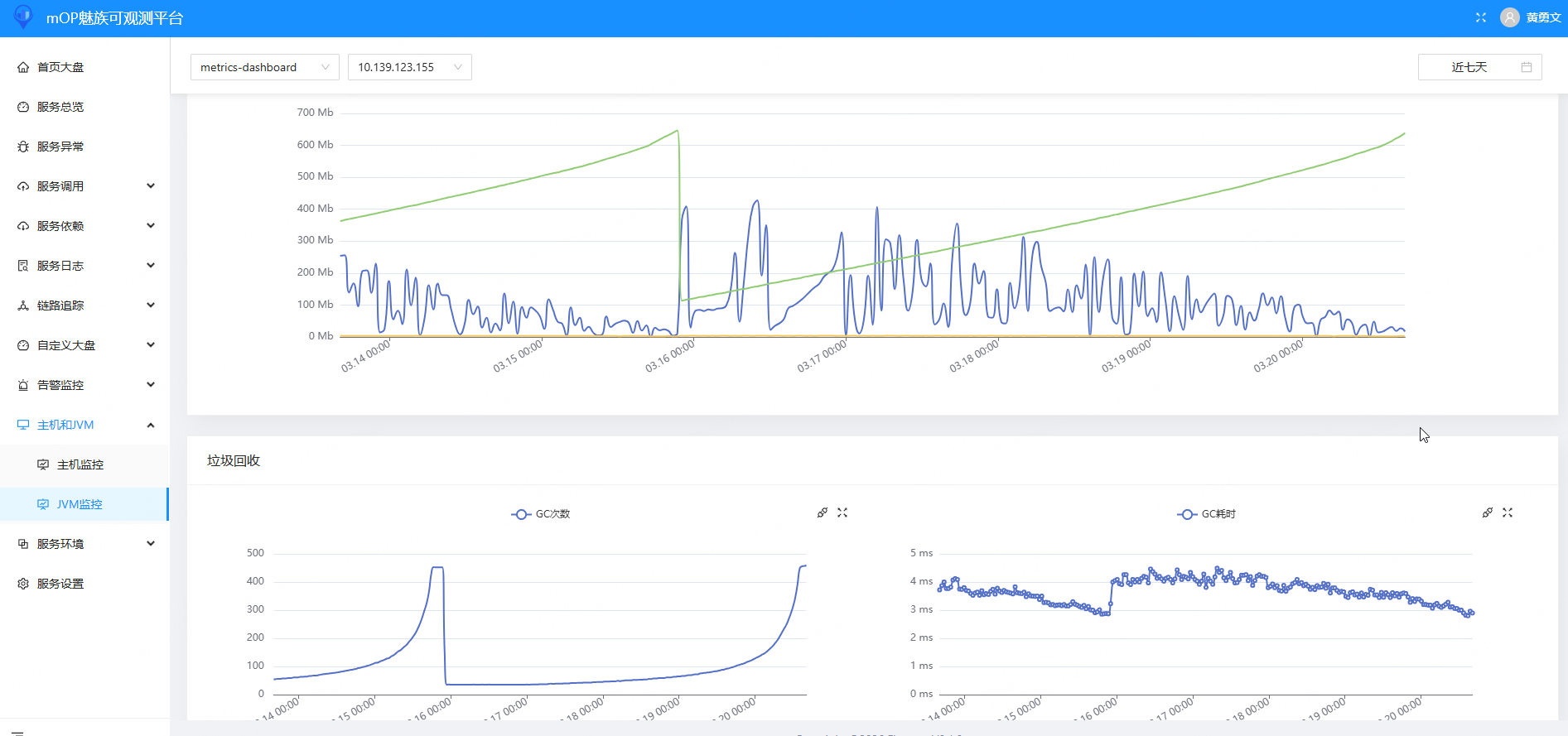
JVM
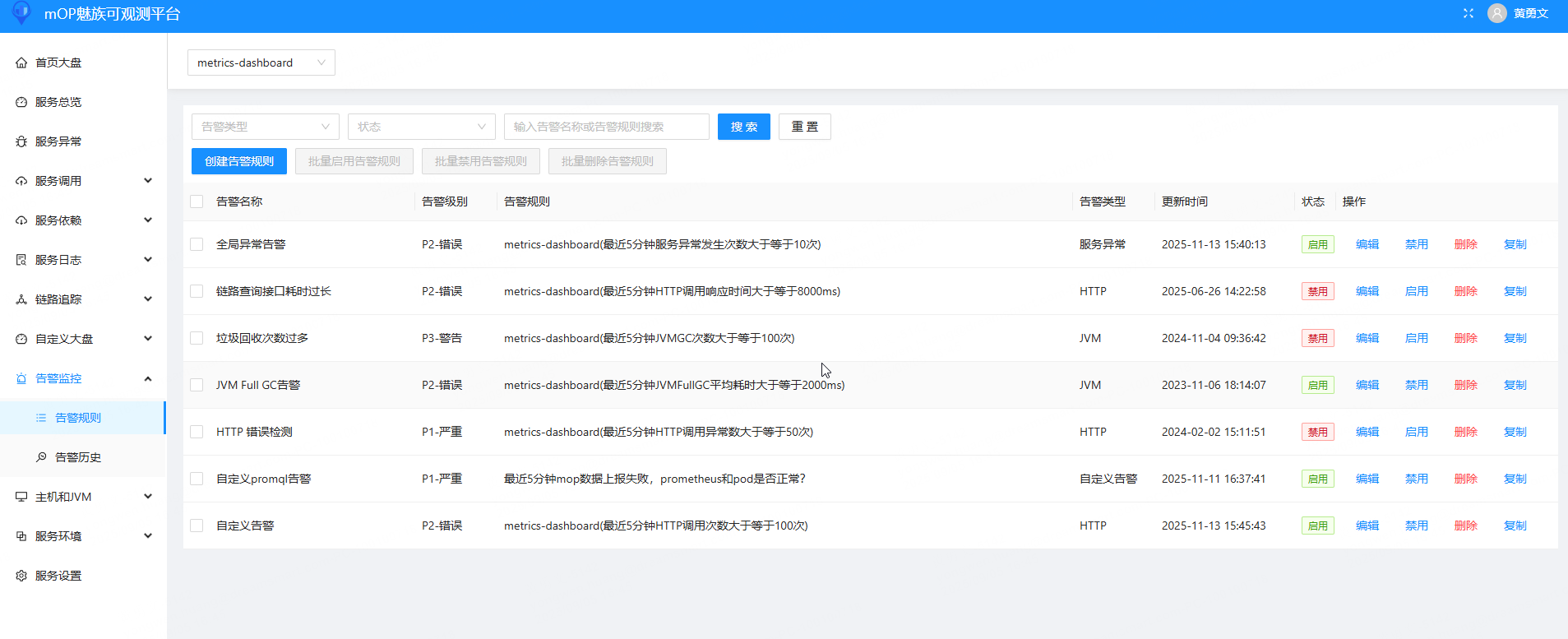
告警:
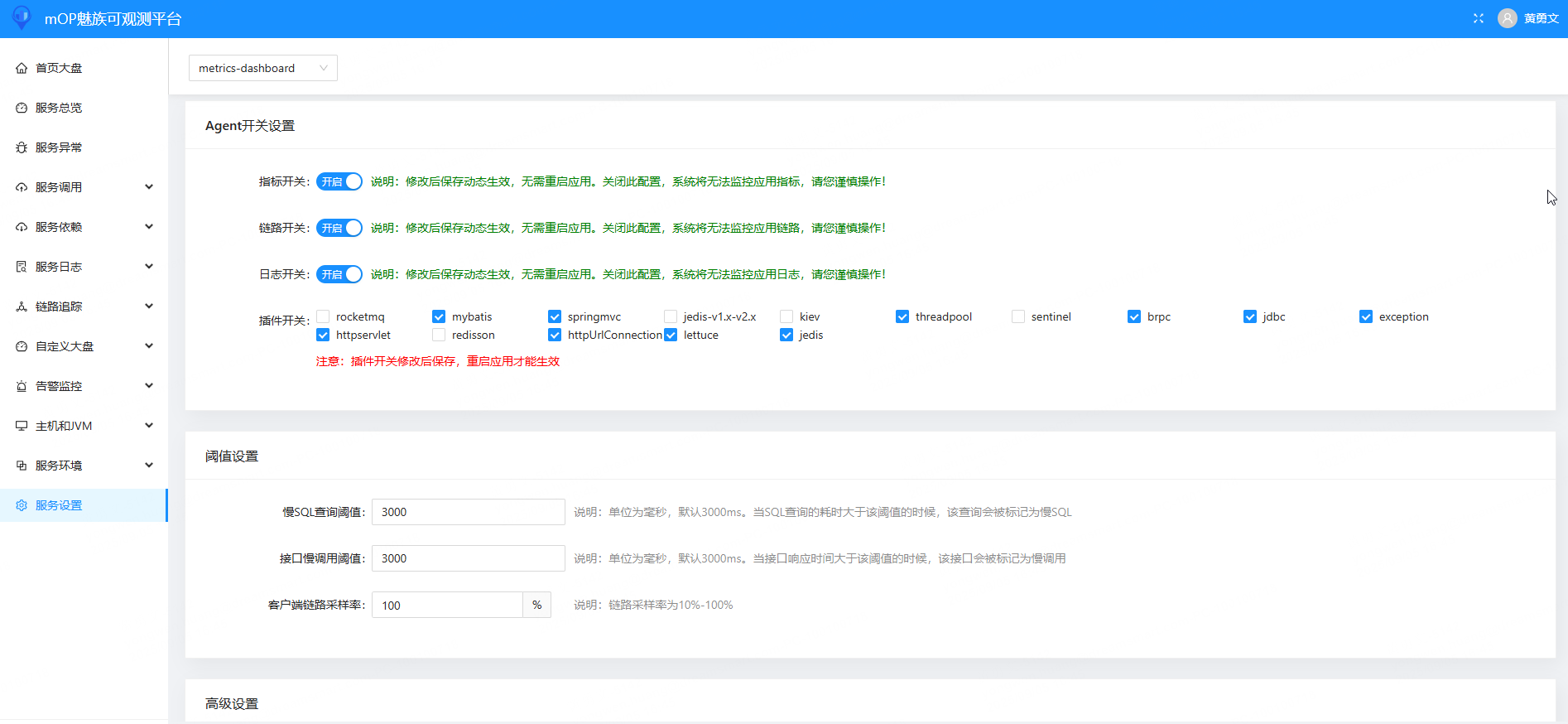
服务设置:
# 改进
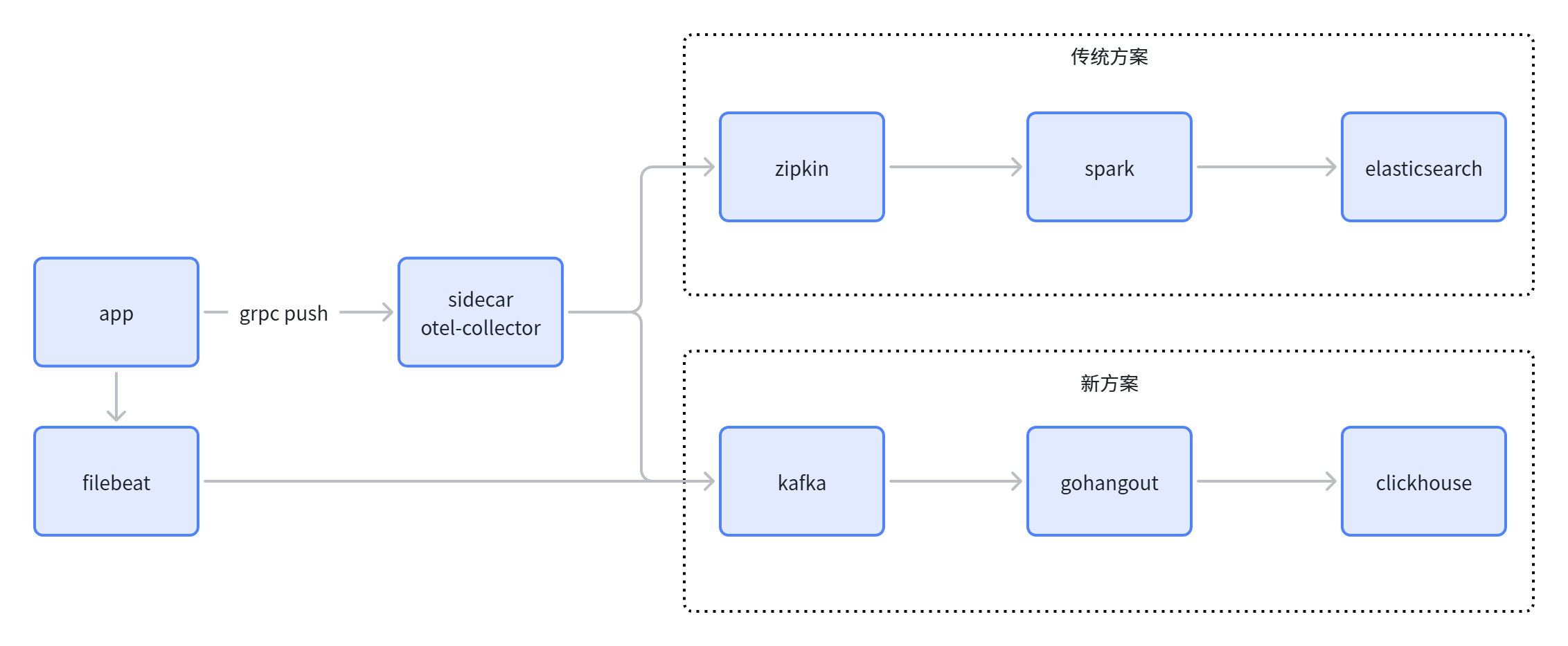
# 引入clickhouse
在没有可观测平台前,团队使用的是ELK体系(Filebeat -> Logstash -> Elasticsearch -> Kibana),es带来了以下问题:
- 在 ES 中比较常见的写 Rejected 导致数据丢失、写入延迟等问题经常出现
- 团队人员对于ES的语法使用成本较高,且难以定位自身业务的索引,导致查询效率过低
- 最致命的问题是ES的服务器成本过高,磁盘空间占用越来越大
此时开始注意到ClickHouse,一方面 ClickHouse 的数据压缩比比 ES 高,相同数据占用的磁盘空间只有 ES 的 1/3 到 1/30,节省了磁盘空间的同时,也能有效的减少磁盘 IO,这也是 ClickHouse 查询效率更高的原因之一;另一方面 ClickHouse 比 ES 占用更少的内存,消耗更少的 CPU 资源。我们预估用 ClickHouse 处理日志可以将服务器成本降低一半。
而且 ClickHouse 采用 SQL 语法,比 ES 的 DSL 更加简单,学习成本更低。
同时复用原来的Kafka服务,在升级过渡阶段,只需要消费历史的kafka日志数据即可,这样就可以做到业务无感知。
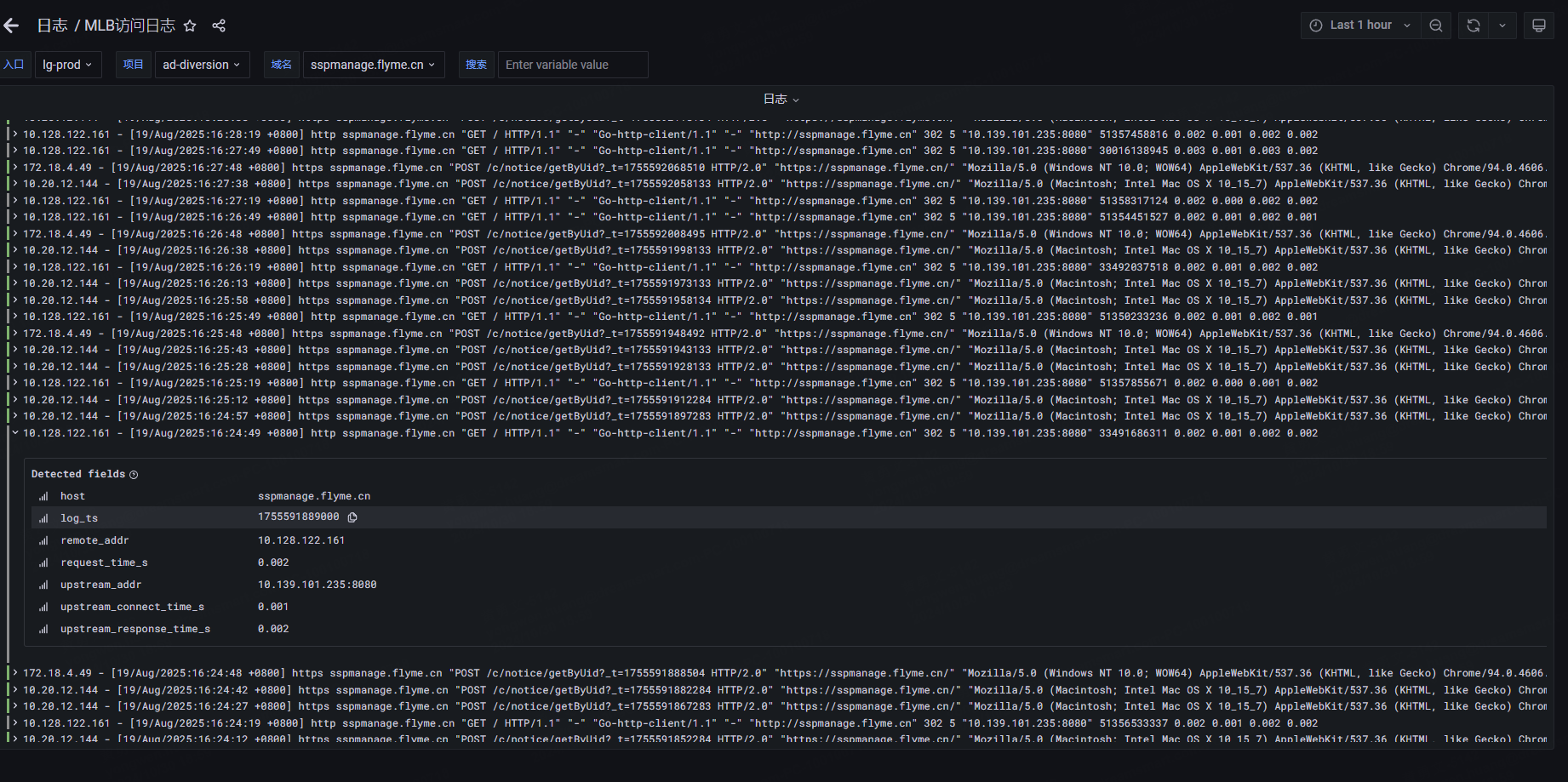
同时,对网关日志、k8s日志进行收集并入库到clickhouse,展示方式可使用 grafana:
# 引入vmagent
prometheus server在pull 应用指标的时候,经过一段时间,经常发现 OOM 的情况,而且prometheus还不方便采用集群模式部署,所以一旦重启,指标会出现断层的情况。
这个根本原因是prometheus的核心架构设计决定的,这是prometheus的架构:
[Targets] → [Prometheus Server]
↓
[内存] ← 所有数据先到内存
↓
[磁盘] ← 定期写入
↓
[查询] ← 查询时读取内存+磁盘
Prometheus 的所有操作都在内存中进行,Target过多加上磁盘写入速度过慢的情况下,它就会出现OOM。
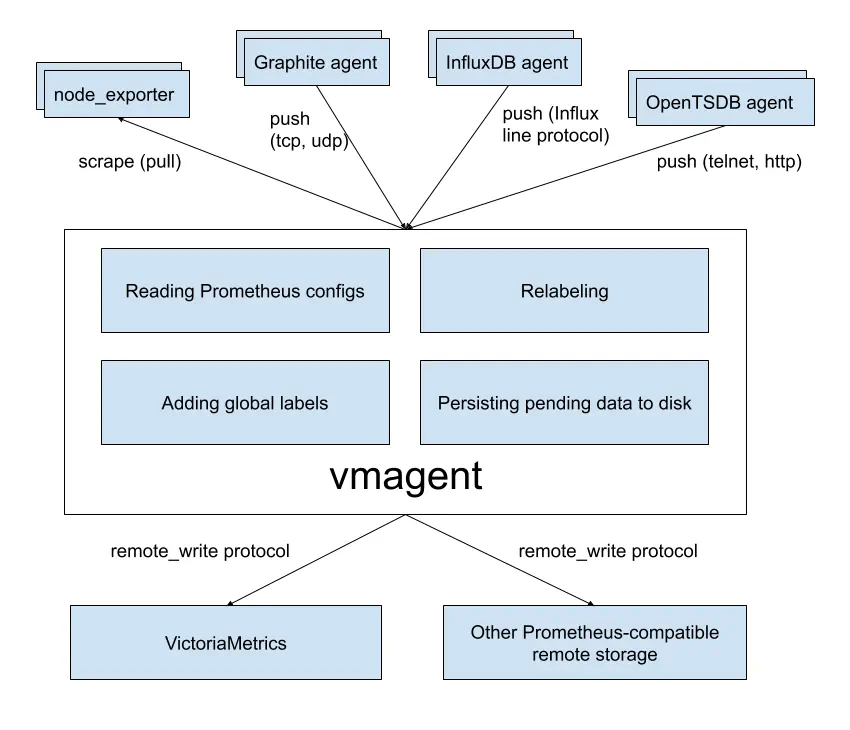
victoriametrics 家族有一个叫做vmagent的替代品,vmagent 只转发不存储
[Targets] → [vmagent] → [Remote Storage] ← [查询时]
↓ ↓
[内存缓冲] → [立即转发] → [不存数据]
(最小内存)
总结就是:
| 特性 | Prometheus | vmagent | 内存差异原因 |
|---|---|---|---|
| 数据存储 | 内存+磁盘 | 只转发不存储 | Prometheus需要维护完整的TSDB |
| 索引 | 完整倒排索引 | 无索引 | Prometheus为快速查询建立索引 |
| 压缩 | 内存压缩后写入 | 不压缩 | Prometheus压缩需要内存缓冲区 |
| 查询 | 本地处理 | 不处理查询 | Prometheus查询需要加载数据 |
| 聚合 | 支持recording rules | 不支持 | recording rules在内存计算 |
对其进行测试发现,内存占用对比如下(100万时间序列)
Prometheus: ~8-10GB RAM
vmagent: ~1-2GB RAM
