 一致性hash算法
一致性hash算法
在上一篇Redis主从、哨兵、集群的区别 提到了Redis的常见架构。
在使用Redis集群的时候,为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,即每台redis存储不同的内容;内存/QPS不受限于单机,可受益于分布式集群高扩展性。
那就一个问题来了:假如我们有三台Redis机器组成的集群,如何才能确保每个key落在不同的Redis单机上呢?
这个问题好比MySQL的分库一样,如何把不同的id落到不同的库,其实简单的求余就可以了,假如有3个库,id % 3 即可。
Redis也可以做到。
Redis也可以使用 hash算法进行分配,比如说 有一个 名为 HelloCoder的key,hash(HelloCoder.png) % 3 = 1 就可以知道这个key落在哪台服务器了。
这种方法乍一看,也没什么问题,一次性就能定位到了哪台服务器,也不用轮询了。
但是,万一某台服务器挂了,需要把这台服务器做故障转移;或者说我要加一台服务器,这样的话,取模后所有的位置就发生了变化。
所以为了解决这种方法,就诞生了Hash一致性算法
以下引自:
作者:oneape15 链接:https://www.jianshu.com/p/528ce5cd7e8f
一致性Hash算法也是使用取模的方法,不过,上述的取模方法是对服务器的数量进行取模,而一致性的Hash算法是对2^32取模。即,一致性Hash算法将整个Hash空间组织成一个虚拟的圆环,Hash函数的值空间为0 ~ 2^32 - 1(一个32位无符号整型),整个哈希环如下:
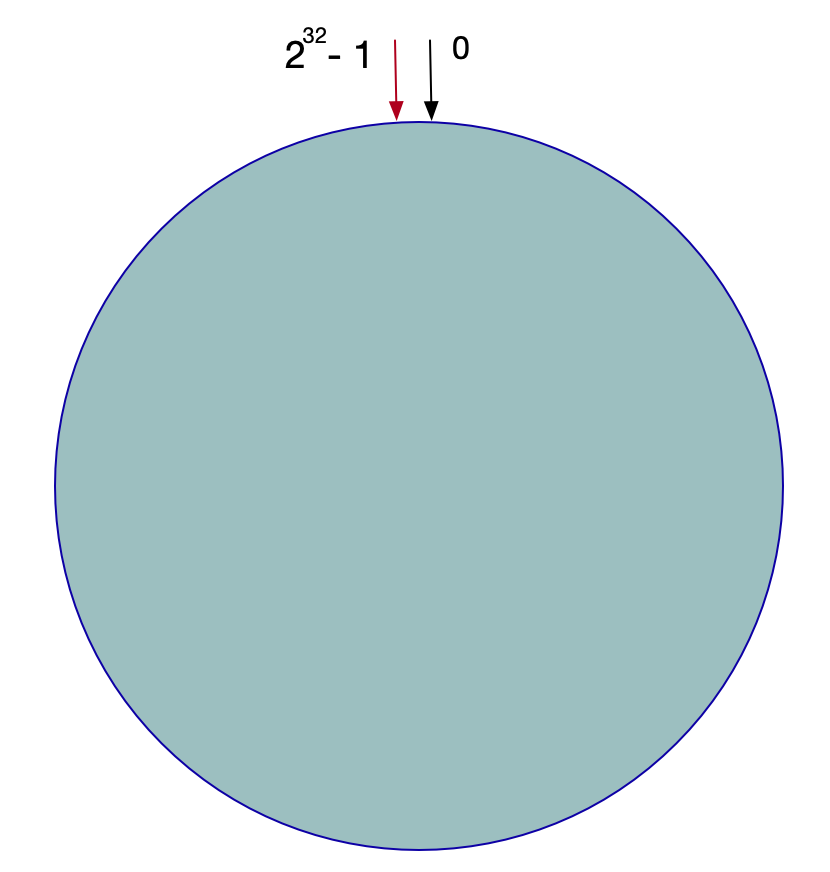
整个环从0位置开始,顺时针方向。
我们可以把服务器的IP进行求hash,然后再和2^32取模,然后确定一个位置,比如我们有三台机器,使用IP地址哈希后在环空间的位置如图所示:
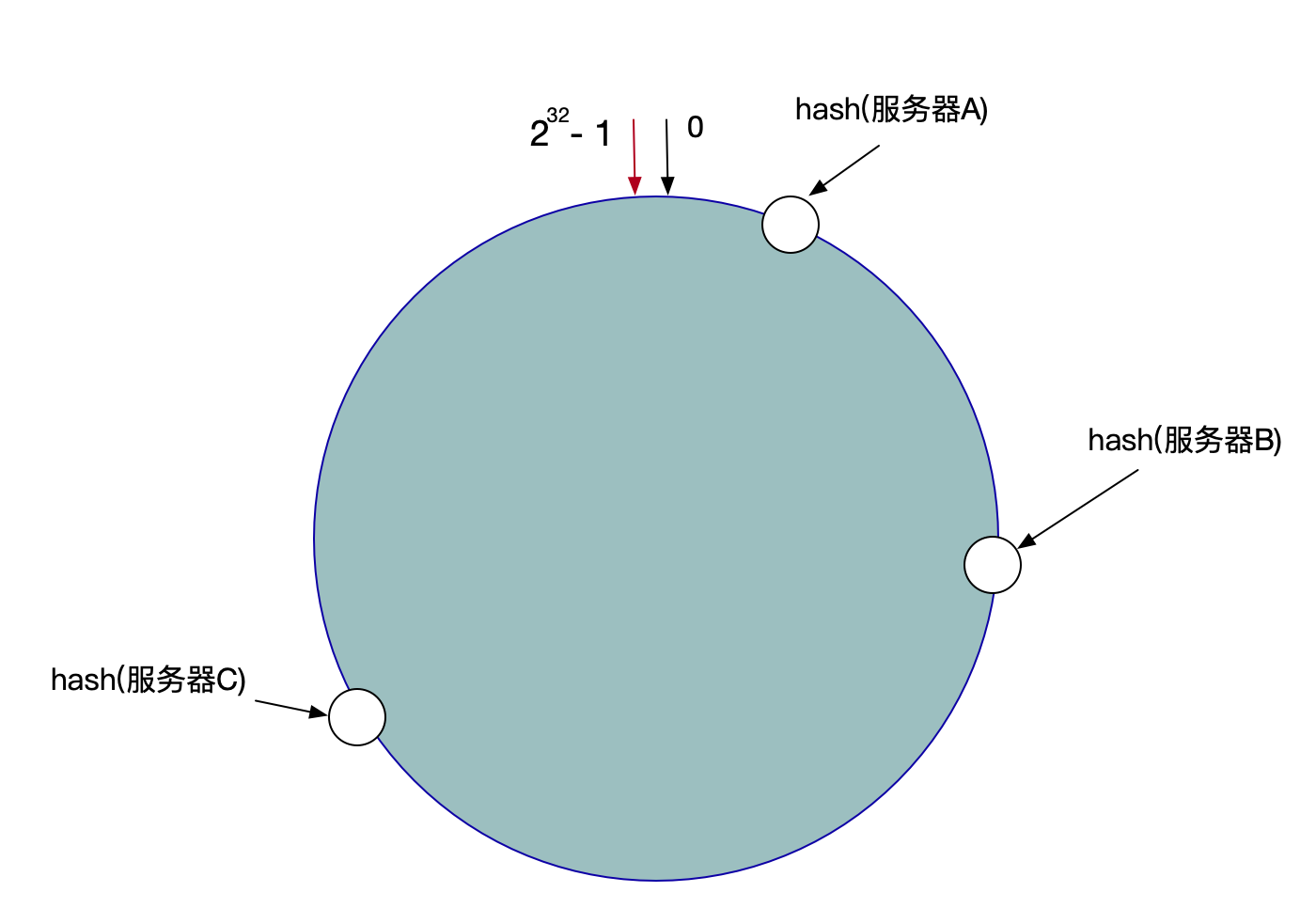
(当然这个hash后的节点可能是不均匀的)
然后呢,将数据Key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针查找,遇到的第一个服务器就是其应该定位到的服务器。
例如,现在有ObjectA,ObjectB,ObjectC三个数据对象,经过哈希计算后,在环空间上的位置如下:
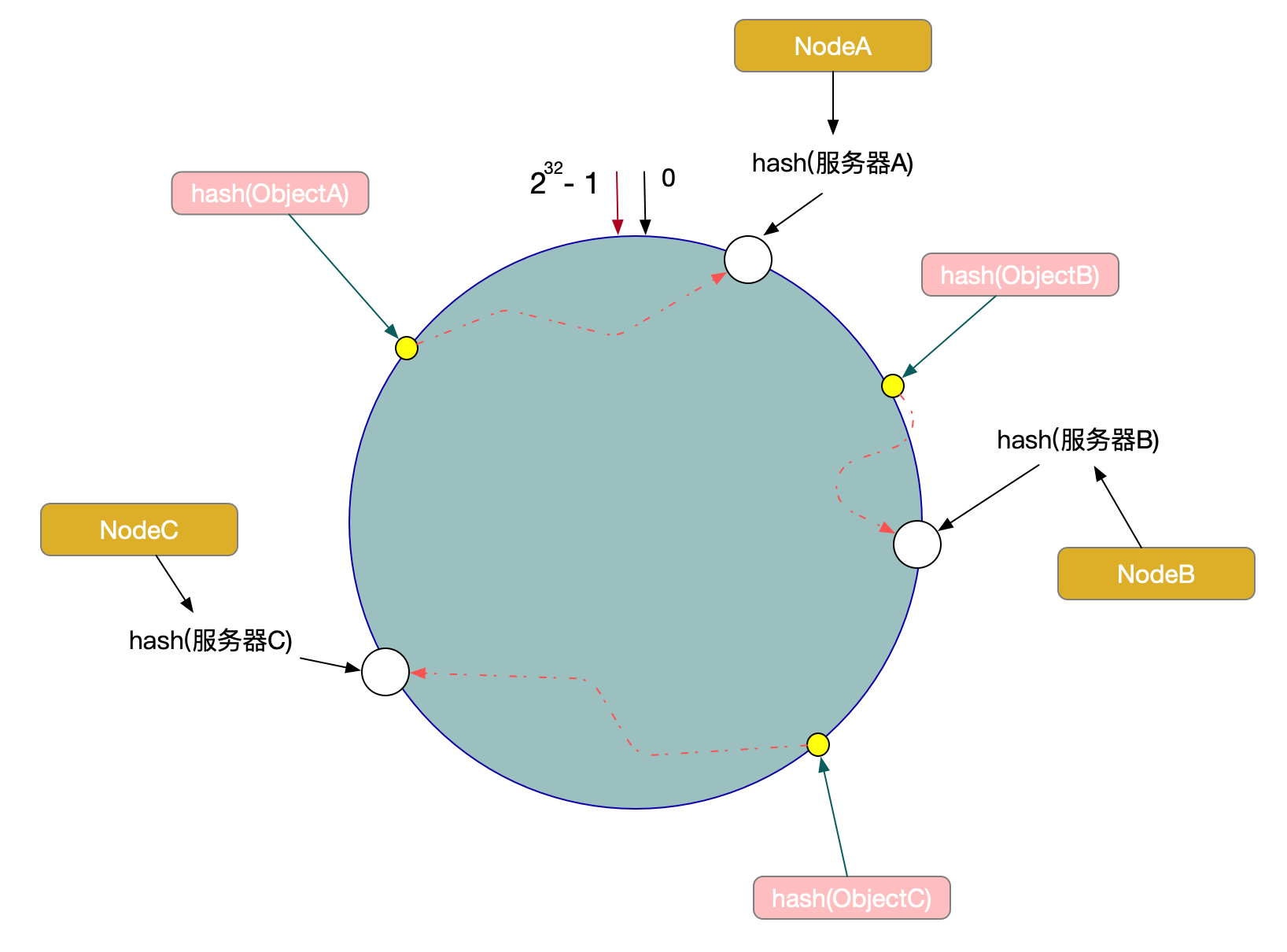
根据一致性算法,ObjectA -> NodeA,ObjectB -> NodeB, ObjectC -> NodeC
容错性:
假设我们的Node C宕机了,我们从图中可以看到,A、B不会受到影响,只有Object C对象被重新定位到Node A。所以我们发现,在一致性Hash算法中,如果一台服务器不可用,受影响的数据仅仅是此服务器到其环空间前一台服务器之间的数据(这里为Node C到Node B之间的数据),其他不会受到影响。如图1-6所示:
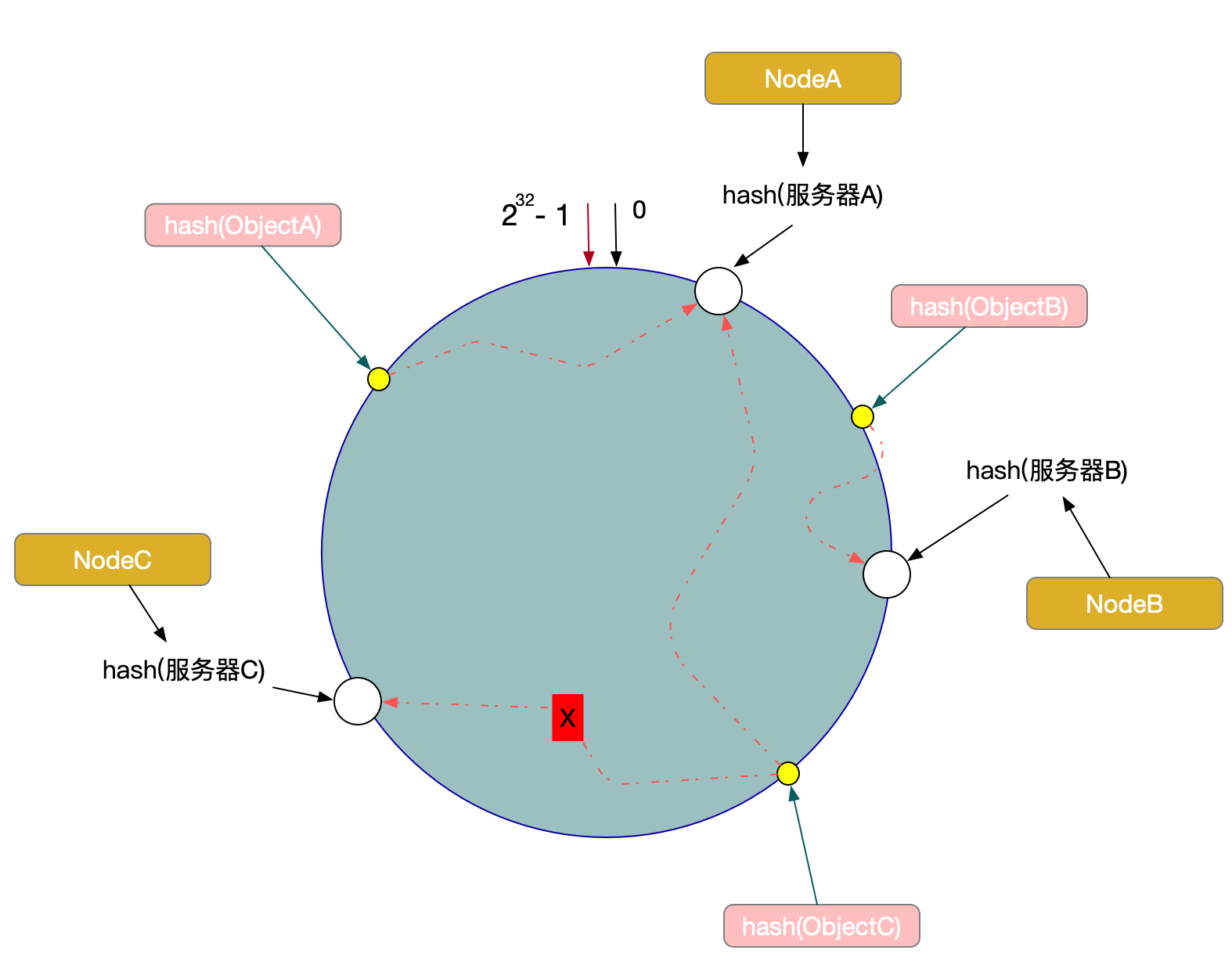
另外一种情况,现在我们系统增加了一台服务器Node X,如图所示:
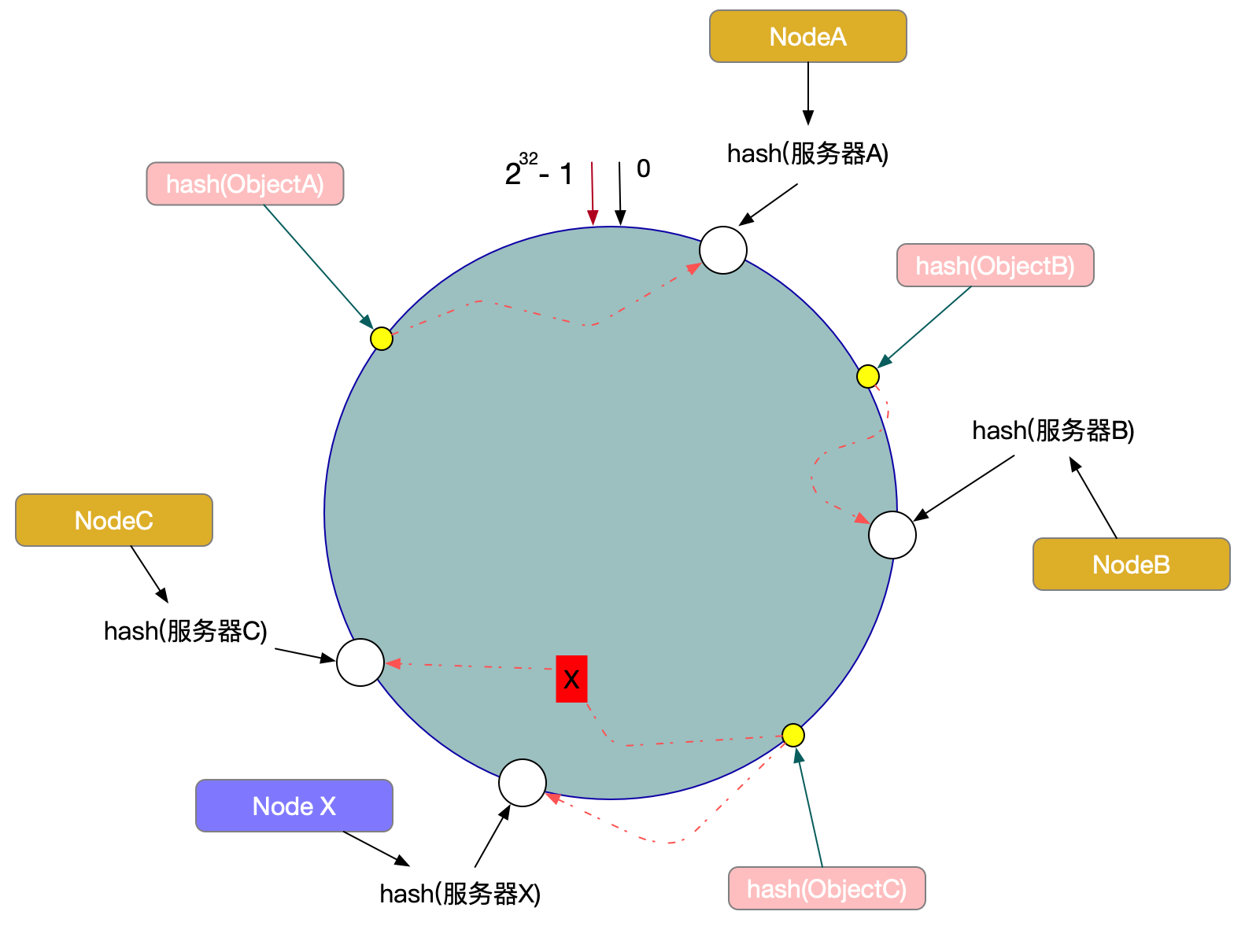
此时对象ObjectA、ObjectB没有受到影响,只有Object C重新定位到了新的节点X上。 如上所述:
一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,有很好的容错性和可扩展性。
数据倾斜问题:
在一致性Hash算法服务节点太少的情况下,容易因为节点分布不均匀面造成数据倾斜(被缓存的对象大部分缓存在某一台服务器上)问题,如图:
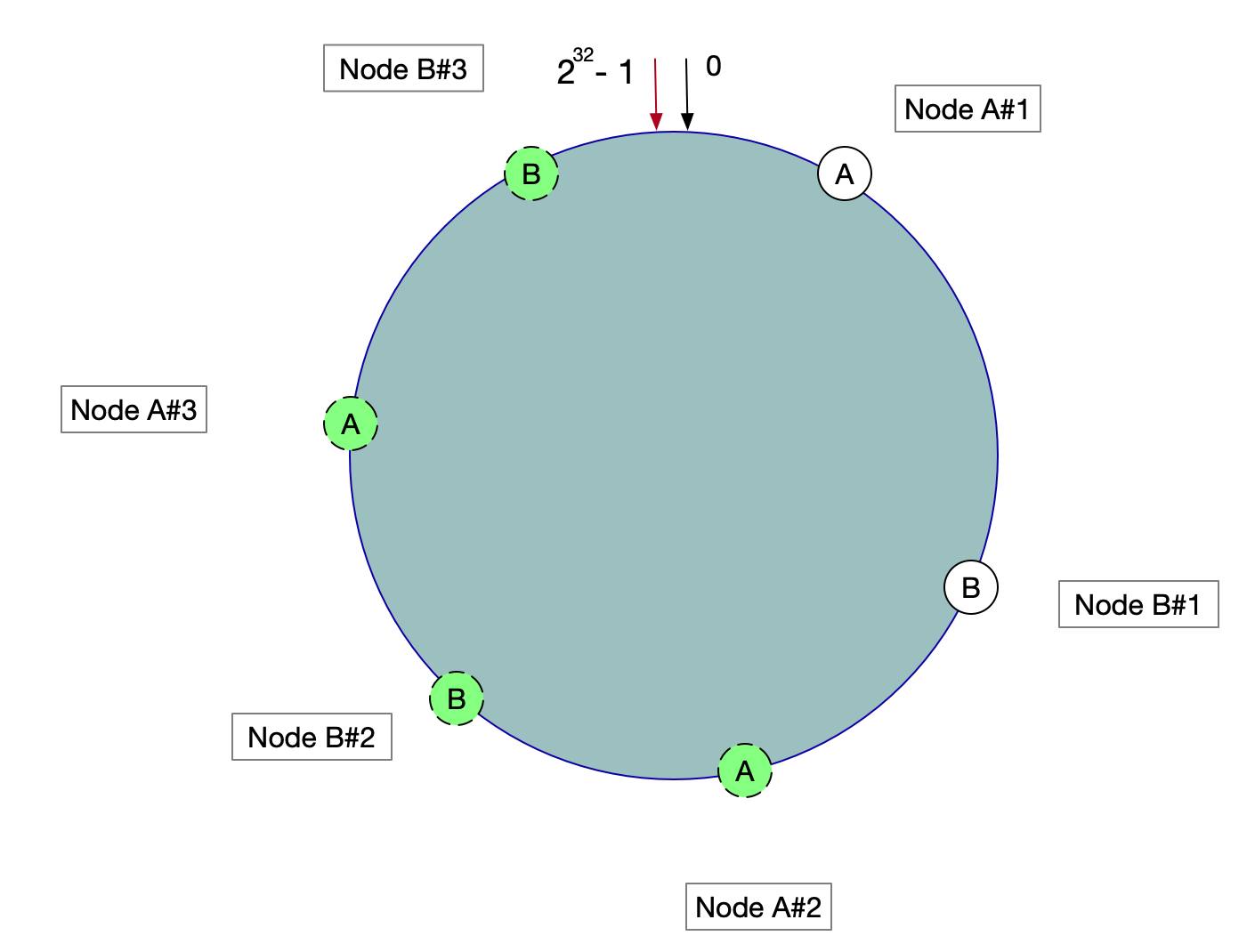
这时我们发现有大量数据集中在节点A上,而节点B只有少量数据。为了解决数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务器节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
具体操作可以为服务器IP或主机名后加入编号来实现,实现如图所示:
数据定位算法不变,只需要增加一步:虚拟节点到实际点的映射。 所以加入虚拟节点之后,即使在服务节点很少的情况下,也能做到数据的均匀分布。